My journey about implementing an HCL parser in pure Go
One of my new side projects was about a scanner/parser family written in pure Go for the Hashicorp Configuration Language. I had two reasons for it, the first one was to have fun and learn the internals of Go’s own parser family (go/{ast,token,scanner,parser}) and the second one was to have a hclfmt command, just like gofmt, which would format an HCL file based on predefined set of rules. (The original HCL parser was generated with Yacc. It works totally fine, but it was not as flexible as compared to an handwritten parser)
I’ve successfully finished this project and announced it on Twitter last week:
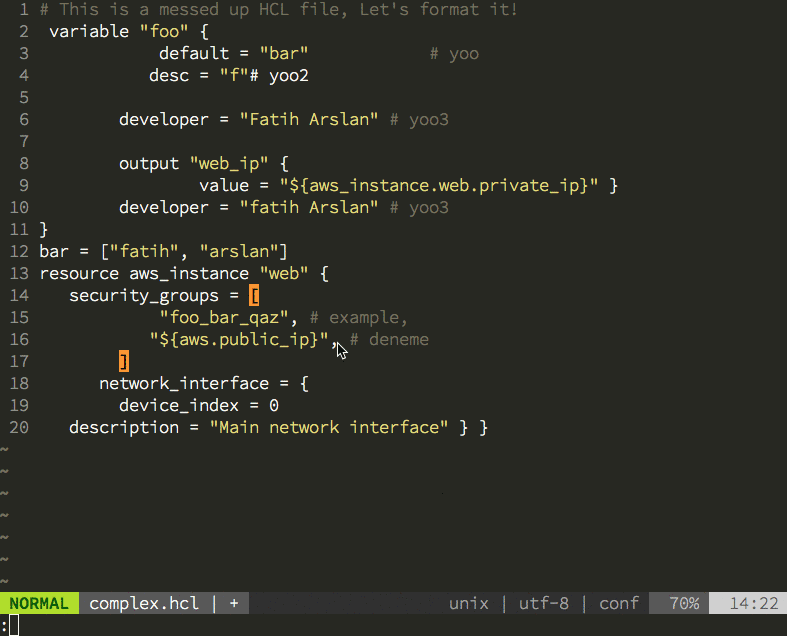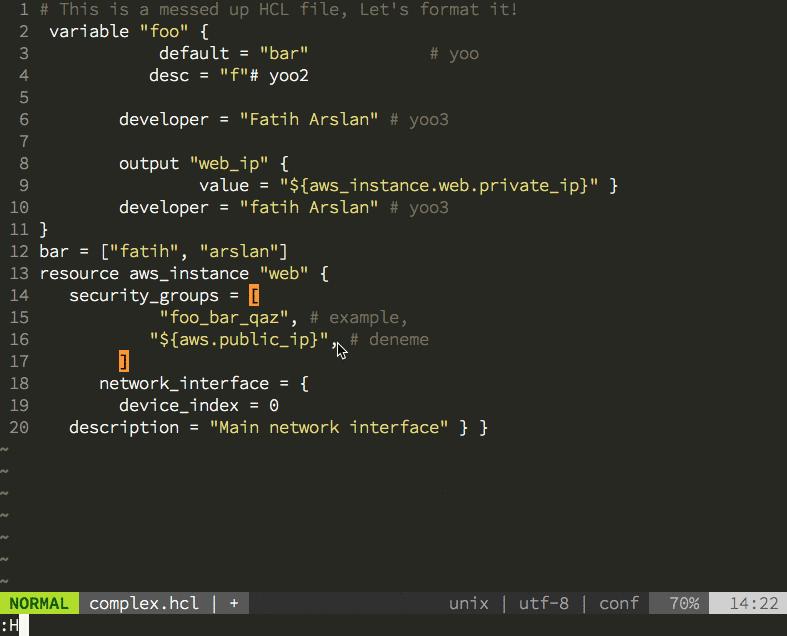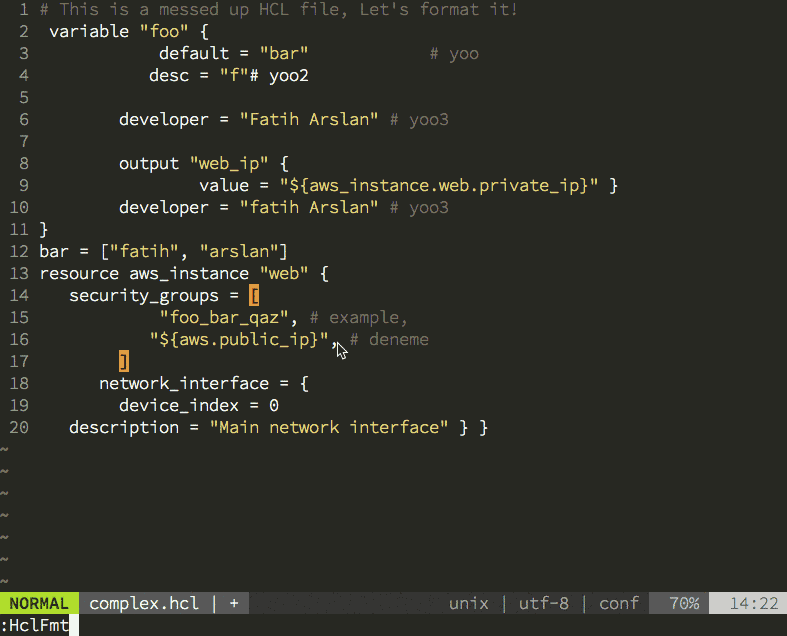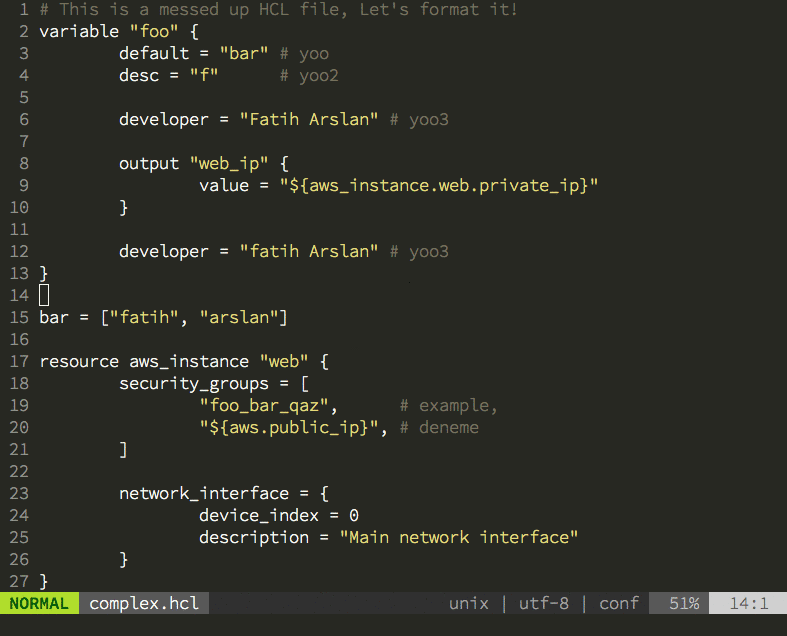
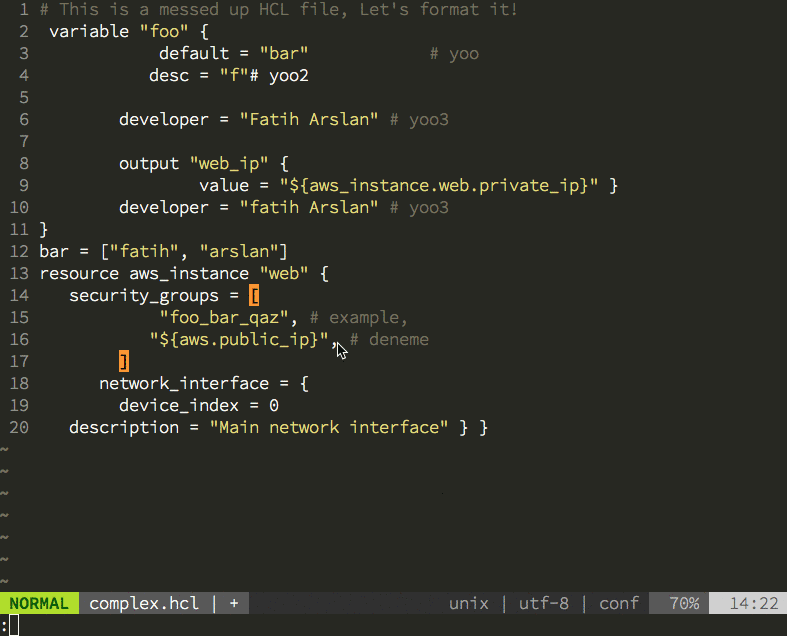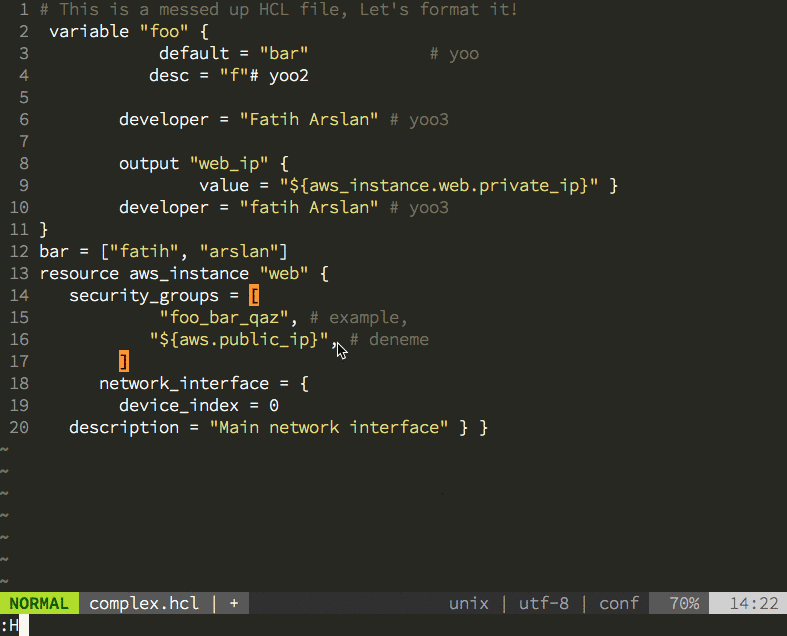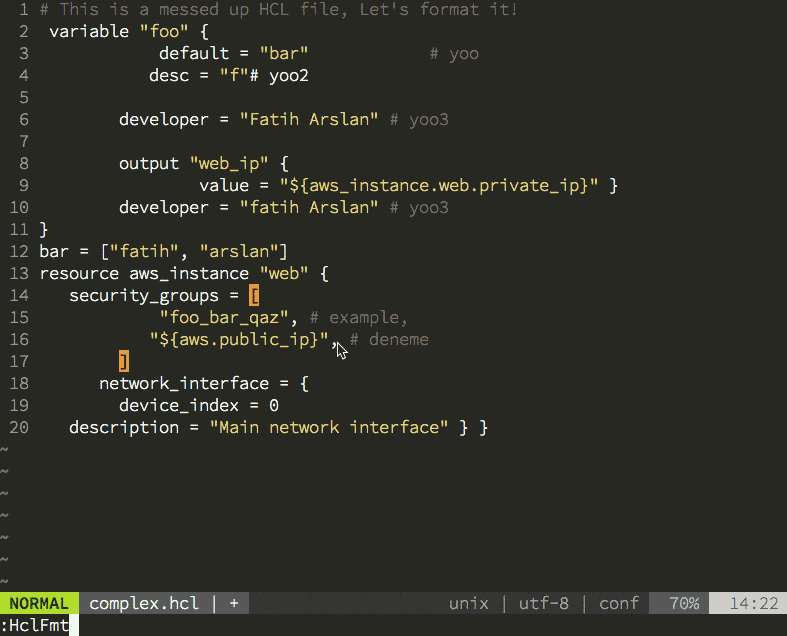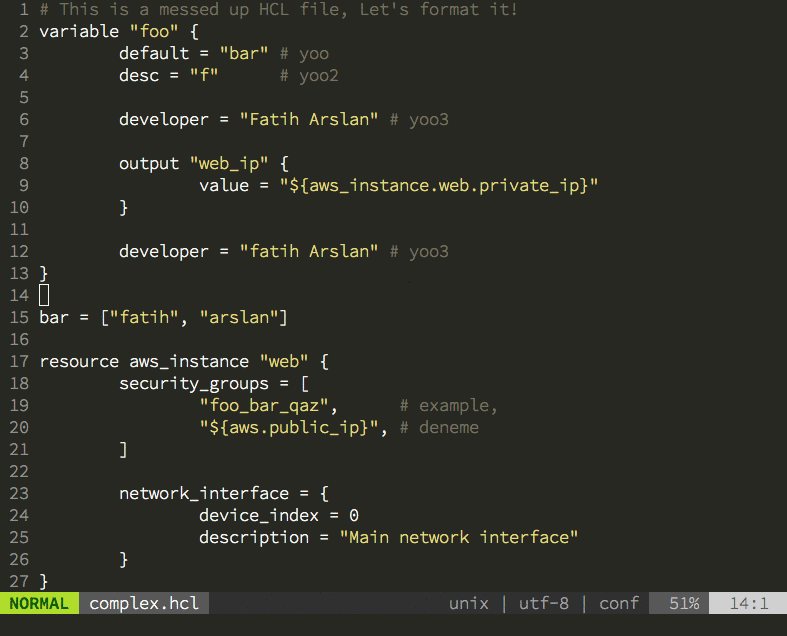
Having the new parser family also allowed me to create the hclfmt command. It can be called from the command line or integrated into and editor (via a save-hook). This is how it looks in action:
I’ve learned a lot of things while implementing the packages. Some parts were really easy and fun, but some details really was challenging. Here are my thoughts:
- Go’s own parser family is really well written. It helped me tremendously for shaping the inner complex systems of the parser.
- The tests of Go’s scanner are again well written. It tests cases which I’ve never thought would be a problem. Even though it’s an overkill for the HCL parser, it was still good to know the limits (btw I’ve added all of the edge cases).
- Defining the tokens and writing the lexer(scanner) was the best part of this project. I don’t know why, but having a stream of tokens from an HCL file felt good. My previous post about this explains some of the details: https://medium.com/@farslan/a-look-at-go-scanner-packages-11710c2655fc
- I’ve changed the AST several times. I think part of this was because how HCL was defined in parse.y (the grammar of the syntax written in yacc). Everything was an object, thought objects would differ based on the context and how they were defined (such as lists).
- The most challenging part was creating the** printer and parser**.
- Parsing comments was hard. I couldn’t decide how to deal with them in the first place. I thought associating them with the AST would solve it (I was wrong). Later, reading the Go parser, it was obvious that I had to store all comments separately from the AST, but also associate lead and line comments with some of the AST nodes.
- Because of comments, printing them was hard too. We had three kind of comments. Lossy comments were comments that are not associate with any kind of AST node. They could be anywhere. Lead comments were comments which didn’t have any newline between their next non COMMENT token. And lastly line comments were comments which would come after the token and would be on the same line.
- Aligning one liners, with their comments would require me to make additional lookahead scans. That part was challenging but also fun.
- I had a lot of **recursive stack overflows **during the initial parser implementation. Adding a log tracer was something really helpful to negotiate those.
- I really like Go’s interfaces. Implementing the AST was again fun and easy because of it.
The new HCL parser was received well by the community. Some of the Hashicorp employees wanted to talk with me about possible integration and replace it with their current parser.
In the end Mitchell himself (CEO of Hashicorp) contacted me about how we could move forward with this parser. I’ve decided to be open and we agreed on moving it to the official HCL repository: github.com/hashicorp/hcl This means that the new parser will be used by all related Hashicorp products (such as Terraform, Nomad, Otto, etc..) and by hundreds of thousands users.
All my commits were moved and merged to the official repo and a thanks statement was added on behalf on me. He also announced it from Twitter. In the end I’ve learned a lot and made a significant contribution to the open source community.