Four years at PlanetScale
It's been four years since I joined PlanetScale. It's also the longest I worked for a company (second is DigitalOcean). I still can't believe how time flies since I accepted the offer to join PlanetScale.
I haven’t shared any of the projects I’ve worked on so far during this period. My LinkedIn profile is essentially empty, and I received over the past years quite a bit questions about my work and responsibilities. In the past I would share a lot about some of my open source projects, but since 2018 I also stopped doing significant work on that area. So I thought now is the best time to reflect that. Second, I must admit I'm pretty bad at remembering what I did in the past, unless I write it down. So it's a convenient excuse for me and share some my past experiences.
Before I start, let me short explain what PlanetScale is and what we do. We offer an extremely, horizontally scalable MySQL database. Straight from our homepage:
PlanetScale is the world’s most scalable and reliable OLTP database. Built on Vitess, our cloud platform is trusted by some of the world’s largest brands.

Before we start, I’d like to shed some light on our work culture. While I’m speaking from my perspective, it’s important to acknowledge that our projects are often the result of cross-collaboration with multiple teams. Any person would know that projects of this magnitude require the collective efforts of multiple engineers working together seamlessly. Hence, I want to clarify that without the help and collaboration of my coworkers, most of it wouldn't be possible.
Second, PlanetScale is a highly flat and autonomous workplace. Almost all our engineers are senior-level professionals with decades of experience in scaling products to millions of users. Employees are accustomed to fixing and implementing workarounds independently. They devise solutions, convince others, and complete projects from start to finish. They require minimal guidance here. Of course, we do planning and have weekly meetings or quarterly alignments. However, within the overall structure, it’s largely autonomous. I know this isn't for anyone, but if you're someone that worked like this before, you would be very happy.
First Year (2021)
My first year, I joined the team that was working on Product side and everything that touches it. So it's all the UX/UI bits, Frontend, our Rails app (which also provides the Public API), the CLI and many other things that doesn't come to my mind. Even though I'm good at building products, I'm not exactly the "Frontend" person you would call. So when I joined, I worked on the CLI and features that needed Go and backend expertise.
We already had a CLI (we named it pscale), but I immediately started improving it with lots of internal changes, refactoring to make it more testable, adding a release pipeline via Goreleaser, making sure everyone on the team could release a new version in SemVer with just pressing a button. It's been 4 years and we still use the same exact foundation I created. It's so easy that everyone on the Surfaces can merge a PR to our CLI repo and release a new version. That's a huge productivity boost. All this is open source and you can find them in our CLI repo.
Next I worked on the pscale shell and pscale connect features. Once authenticated with the our CLI these features would allow us to securely open a mysql CLI shell to our Database, or would open a secure tunnel to our DB on localhost, so if you want you could connect with any tool you wanted (e.g: mysql -u root -h 127.0.0.1 -P 3307). Of course this simplicity was implemented with several backend additions, such as a Go reverse proxy that was able to parse the MySQL protocol. This was one of my biggest projects that year. We used it for several years until our Edge team replaced with a far more superior implementation. It was good for what we did at that time, and with all good things, it was time to replace it with more performant implementations, allowing us to expand our products with new features.
Since I've joined, I also started working on other Go services that weren't directly related to the Product Team. I started making a few contributions, mostly making it more Go idiomatic, adding tests, improving the state of CI, etc.
Eventually, this led to my moving to our partner team. I contributed so much that I was at some point the diplomatic person between these two teams, so it was very easy for me to transition. The new team was a lot more aligned with my skills and past work experience. It was all about Go RPC services, distributed systems challenges, and running workloads on Kubernetes, via an Operator (eg: using controller-runtime). Since then I'm with my current team (and currently the oldest member of the team). We're in the cross section of our Product Team and our Infrastructure/Database (Vitess) teams.
After joining the new team, I took on various responsibilities. I significantly enhanced our observability capabilities by adding tracing, improving error and panic reporting, and improving our RPC service with numerous small, yet impactful improvements.
One of the latest projects I've done in 2021 was to implement a distributed lock based on DynamoDB's conditional writes. We use the distributed lock in our control plane for certain actions that require diligent and care. Of course our Kubernetes operator is completely idempotent, but there were are few internal services requiring us to be cautious. I cannot share what I've did there, but Clever has a similar open source project if you're interested: https://github.com/Clever/dynamodb-lock-go
Second Year (2022)
This year was the year where I slowly deep-dived into how Vitess works en grande. At the beginning, I was working with our control plane RPC service, but with time, I also started taking a stab at our Operator. I had extensive experience already with Kubernetes due to my past work at DigitalOcean. I was not only on the founding team that built Kubernetes at DO from scratch, I also worked on several CSI-related projects, even wrote one of the longest and most detailed blog posts about how to implement a CSI Container Storage plugin.
The biggest challenge here wasn’t Kubernetes, but rather another CNCF project: Vitess. Although we’re a database company, I had never worked with databases before. However, I had been familiar with Vitess for a long time, and eventually, I had to make significant changes and overcome my fears. The best way to overcome such challenges is to actually take on a difficult task and tackle it head-on. This advice has been repeated to me countless times in various literatures. Whenever faced with two options, one easy and one challenging, always choose the latter.
So hence, my first big project was to implement the deployment and management of multi region clusters. I started working on making our Databases to work across multiple regions. This was a big project for the company, and also probably a tipping point for me at PlanetScale. I had to finish and implement it. There was no other way.
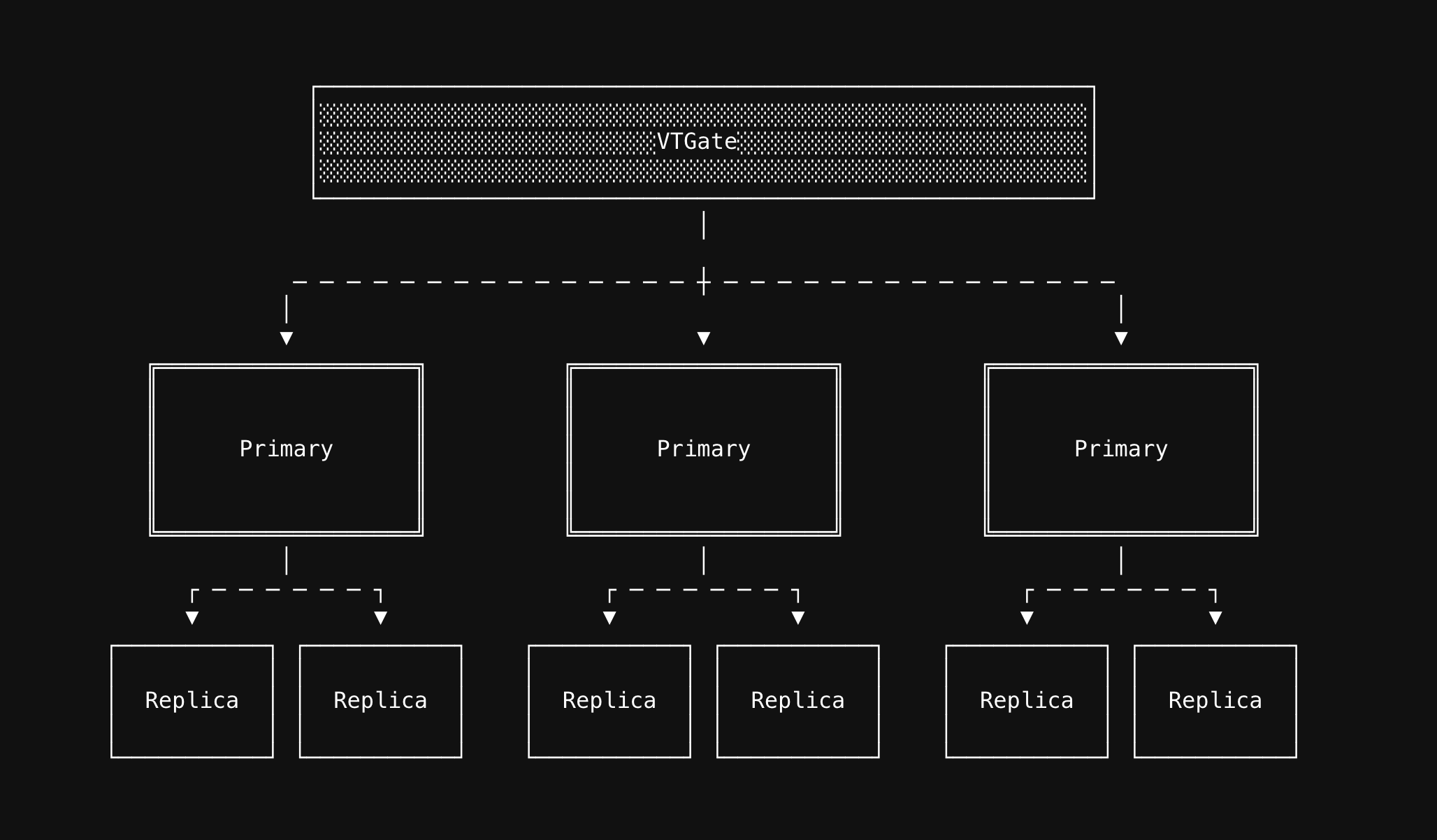
Vitess already is capable of supporting multi region clusters, but our control-plane wasn't able to spin up databases that would cross multiple regions. When we talk about multi regional clusters, database experts might have several questions. Is it multi write? Does it only support reads? Does it support fail over? What happens if a region goes down? etc... Our first goal was to implement multi region clusters with a single primary region, and several other read-only regions.
The biggest challenge I had to find out was, how to make operators coordinate between each other, without using any state? Each operator in each region only takes care of databases created in their region. They don't know anything about other regions. Also all our databases, once created, are self-sustained. So they don't have any dependency on any service. We successfully shipped the project after months of work, and we released it in May 2022: "Introducing PlanetScale Portals: Read-only regions" (as a reminder, this project spanned multiple other teams, so I worked with them closely, every team worked on their side of the projects, I don't have to re-iterate it, but it was one of biggest cross-org projects we shipped as a company)
Another big project I worked on in 2022 was autoscaling disks of the DBs. Initially, one of my co-worker started the project, but midway through the project, I took over it. I completed it and released it to production afterwards. This project was also challenging, not like the previous one, but we had to be cautious not to mess up with our customers’ databases. Hence, we slowly rolled it out to the fleet.
The idea here is simple, if the disk usage is over a given threshold, resize it to a bigger size. What was the challenges:
- Because of the operator's idempotent nature, we had to make sure that once a disk was resizing, it was resized (finished) and not-retriggered accidentally. So we had to cautiously make sure to sync the state between the desired and actual value. Because PVCs (i.e: AWS EBS) don't immediately resize, there were a few edge cases we had to take care of.
- AWS only allows us to resize every 6 hours. Once resized, the only way to
growa disk is by recreating it. We don't want to recreate unless we have to (it's possible by creating a new disk with larger size, start a Replica, and then promote it to a Primary, delete the old Replica), so it was important to pick up a good resizing value. Too low, the and the customer might reach the disk size earlier than we anticipated, too large, and we would spend more money than we want to. - Disks have certain limits. For example you can only resize up to 4TB at PlanetScale. So we had to be extra careful not to resize it in a way that would exceed the limit. More on this later.
- Coordination between replicas. Once a disk was resized, it had to be the same across all replicas and regions. Because eventually the replication will catch up, and in theory all disks will have the same disk usage (in practice they might differ, especially if there is replication lag for example).
Finally, beside working several projects, I also worked significantly on our CI/CD architecture for our Control Plane RPC service. It was getting too slow, and becoming unmaintainable. I went over it and completely rewrote our E2e tests, making them 3x faster than previously.
I also worked on the Boost project. It was a caching layer for the database. It' s deprecated, and we no longer provide it as a product. I wasn't heavily involved on our end, but kickstarted the project to deploy the components needed for the database to work with the caching layer. My friend Matt Layher was the main person involving with Boost on our end, and he then finalized, implemented the main logic (API and several other things ) and shipped it to production.
Third Year (2023)
PlanetScale provides an import tool in the dashboard that allows you to painlessly import an existing internet-accessible MySQL or MariaDB database into a PlanetScale database with no downtime. In 2023 I worked on several improvements regarding database imports. One of them was the ability to support importing multiple external databases at once. One of our largest customers had a need for it to reduce the load on their primaries.
Next up, I worked on improving our current multi-region clusters. Initially, when I implemented it, it had a few shortcomings. These were mostly internal implementation details (not user-facing). One of them was a big blocker for a feature we wanted to add later: Regional Failover. The idea here was to be able to convert an existing Primary region into a Read-only region. Even though it looks easy, making sure all the intermediate data structures had the correct state, without zero downtime, was a big challenge. Once that was finished, we also worked on supporting Read-only replicas in the same region as the primary (nit: the main bodywork was done mostly by my coworker Alex Noonan, but I tagged alongside). This was a specific use-case for a large customer. Most of these features were advanced needs, mostly needed by truly hyperscale companies. They had vastly different requirements compared to a small MySQL shops.
Building on top of this momentum, my biggest work in 2023 was actually implementing regional failover between regions of a multi regional cluster. If you have read so far, you would know that we added support for Readonly regions. Back then your Primary region was static, and you couldn't change that. So you couldn't switch your Primary Replica say from us-west-2 (Oregon, US) to eu-central-1 (Frankfurt, DE). This feature is only available currently for our enterprise users. This was another tipping point for me. I worked with the Infra team to implement a global etcd cluster spanning more than two regions. Beside that I had to make sure that each Kubernetes operator could handle the failover, even though none of them share data between each other.
Other works that I remember working were adding concurrent shard rollouts and auto balancing Replica's across zones. Let me explain these to you.
A Vitess Database (we call it keyspace), might have one or multiple shards. If there are changes to the database that needs to be rollout across a single cluster (i.e: MySQL version upgrade), the operator would update each shard one by one. Until now this was never an issue. But some customers have hundreds of shards for a single keyspace. We're talking about hundreds of replicas. So rolling out a simple MySQL version upgrade will take quite a time. I made the rollout progress to be concurrent, which can be also configured up to certain limit. So it works like a semaphore. This allowed us going forward upgrading keyspaces significantly faster.
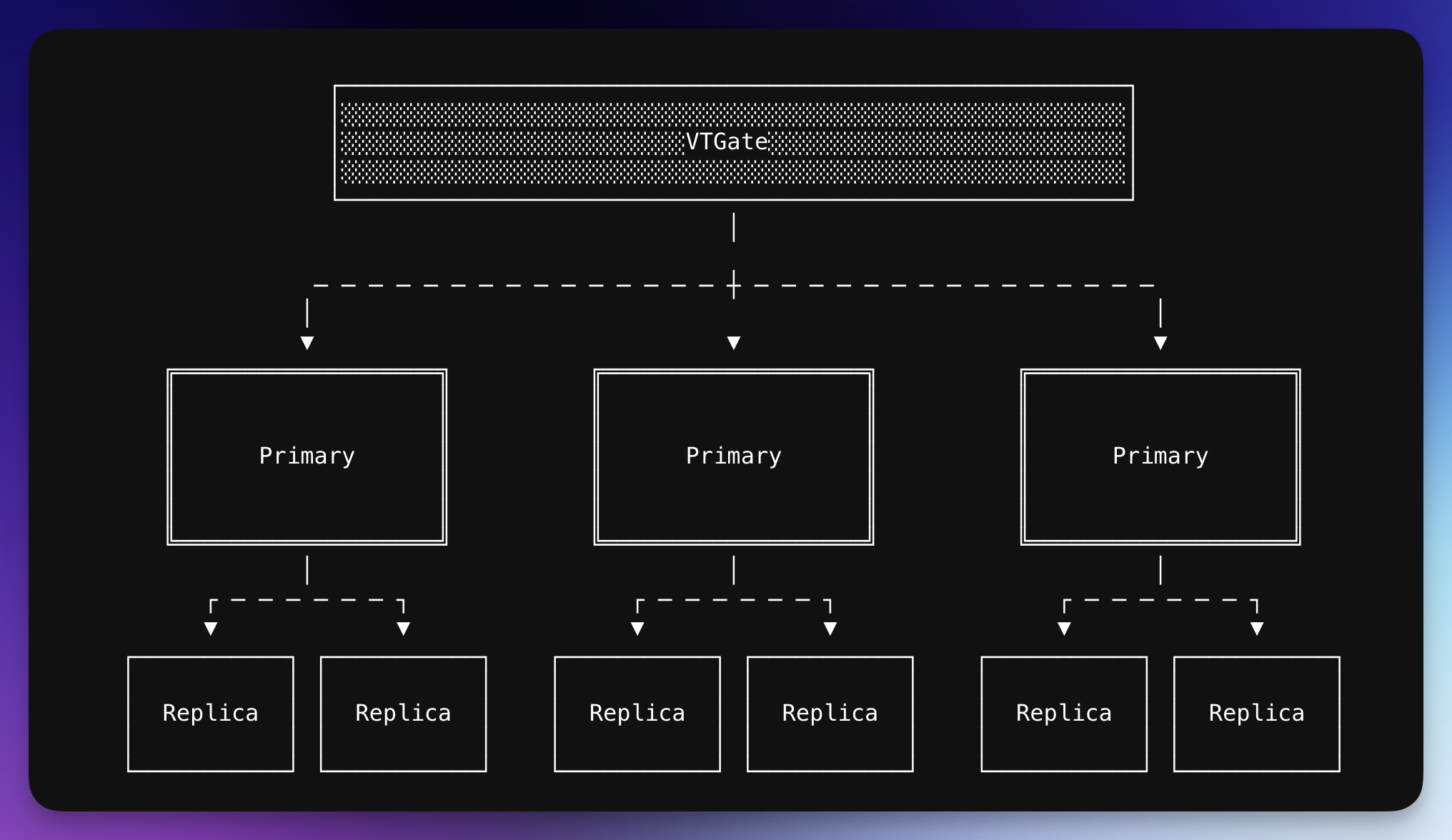
Lastly, auto-balancing Replicas across zones. By default, every cluster at PlanetScale receives three replicas. One of them is the primary, and the other two are referred to as replicas. (I mentioned three replicas because, by default, everything is a replica. However, we can promote one of them to a primary, which gives it a special name.) For a brand new cluster, if the cluster is configured to be deployed to three Availability Zones (AZs), we evenly distribute them. But with this kind of systems, anything can happen that might affect the distribution of the replicas. The underlying node might die, there might be network issues, the replica might become unhealthy, or we might decide to increase the number of replicas (or scale down). So we constantly add and remove Replicas from the system.
Initially, whenever we added a new Replica to an existing cluster, we added it to the most empty Availability Zone (AZ). However, when we expanded the number of AZs or changed the configuration, it would skew the distribution. Once the distribution was skewed, it became challenging to target a specific replica and move it. This is because replicas in our system lack any ordering. They have random names, and their availability can fluctuate. We treat them all the same. This trade-off enables us to scale such a system to its extreme limits.
I worked on implementing a self-balancing algorithm that would require a numerous number of inputs and evenly distribute the replicas across AZs. During the distribution, the algorithm makes sure to never move a primary (unless needed). Sometimes we want to move it, so it's configurable. It also makes sure to not pick up new replicas and instead pick up old replicas (because a new replica might be already put to the correct AZ). There were also very weird distribution issues, here is an example. You can see in us-east-1a there are two replicas:
replica1 in us-east-1a
replica2 in us-east-1a
replica3 in us-east-1bNow there are actually two ways of distributing it, you could change the replicas:
replica1 in us-east-1a
replica2 in us-east-1b
replica3 in us-east-1c
This requires two replicas to be teared down (replica2 moves from us-east-1a to us-us-east-1b, and replica3 from us-east-1b to us-east-1c). Or you could change it to:
replica1 in us-east-1c
replica2 in us-east-1a
replica3 in us-east-1bHere we only moved replica1. This is more efficient because it only requires a single replica to be moved, instead of two.
(nit: I've found out that to properly distribute evenly, with certain constraint requires either dynamic programming or a recursive function that evaluates the output against the input until all replicas are sorted. Just iterating over the existing set of replicas won't work)
Fourth Year (2024)
In 2024, I continued working on various improvements and features. One notable improvement was a new addition to disk autoscaler, which allowed us to shrink disks when necessary. This feature enabled us to scale down disk sizes if customers reduced their data usage. For instance, when customers decrease their data usage, they no longer require a larger disk.
The other improvement we made was the algorithm we used to scale up in case we wanted to increase the size. Previously, we would increase the size in constant increments. For instance, if the disk was 50GB, we would double its size twice, resulting in a 100GB disk. However, for larger disks exceeding 500GB, we would add 250GB (half of its current size). The issue with this approach is that it’s challenging to determine the appropriate scaling factor. Doubling the size isn’t feasible once the data growth slows down significantly after a certain point.
When I looked at it, I could see a pattern. We want to grow very fast, but slow down the bigger the data becomes. So there must be a grow function that exponentially grows, but then switches to a logarithmic scale. Upon some research I've found it, and it's called "Logistic Growth". It's a function that grows exponential but slows down like a logarithmic function. It's used for population growth (i.e deers, bacteria, etc.) where there is an initial size. Initially they grow fast, but then slow down because they are reaching the carrying capacity of their environment. So if you want to say scale something very aggressively first, but slow down when you reach a certain limit, this model is something you could use. The carrying capacity in our case was the maximum disk size limit (e.g: 4TB).
However, the most significant work I completed in 2024 was working on our Etcd clusters. (not the one that Kubernetes uses, but the one that Vitess uses.) Vitess employs a service called Topology, which serves as a distributed locking mechanism and a DB for storing various metadata about the cluster. While there are numerous implementations of Topology, the common implementation is to use Etcd.
By default we use Etcd with 3 nodes. And we have hundreds of etcd clusters. The problem with 3 nodes is the failure tolerance. An Etcd cluster can go down if it loses its majority. With a cluster size of 3, we can tolerate only a single member failure. If two of the nodes are down, we lose the majority and the only way to recover is to create a Etcd cluster from scratch using a previous snapshot.
To improve the situation, I updated all Etcd clusters from 3 to 5 members, allowing us to tolerate up to two failures. In addition to that, all Etcd members are distributed across Availability Zones (AZs), providing us with ongoing operation even if an AZ goes down. All etcd member containers have been updated to use internal AWS and GCP image registry caches, allowing us to avoid interruptions from public registries. On the operator side, the operator is now smarter and safer while rolling out Etcd members. It manages the etcd membership itself, allowing us to simplify rolling out members without having to remove/add members to the etcd cluster manually. All these changes resulted in a more stable and resilient system that is easy to maintain. And of course, after months of work, I wrote an extensive FAQ and How-to documentation and shared my findings with the team, making sure the knowledge is preserved in the future.
Finally, even though we were in a much better position, there was one more thing. I wanted to also make sure that we could reinstiate an Etcd cluster, even if it completely lost all their members. Etcd has an extensive document that describes how to recover from a disaster: https://etcd.io/docs/v3.5/op-guide/recovery/ But it wasn't easy to apply these guidelines to our internal systems, because most of what is described isn't as easy appliable as it looks like. For one, we cannot just run a random etcd command against an Etcd cluster. Everything is secured and only certain services or entities with access can run them. So just around Christmas, I did several experimentations on how we could recover and added several improvements that allows us now to recover from a disaster. Now I could rest in peace.
Verdict
Wrapping up, there were many, countless other things I could probably add here, but looking back I realized that I'm lucky to be working in such a challenging environment. All my coworkers are very good at what they do (thank you, folks!), they give me confidence, and I know I'm talking to genuine and smart people. It's rare to find a place you can enjoy, but for some, it's also important to push their limits whenever they can. And you can't do that alone; you need to have support.
One crucial aspect was that my manager and leadership consistently believed in my ability to work on projects. They trusted me to tackle significant challenges, and I am grateful for their unwavering support. Let’s see what the upcoming year 5 brings. We have an array of exciting new improvements and features in the pipeline. I'm looking forward to showcasing them to you all.