The ultimate guide to writing a Go tool

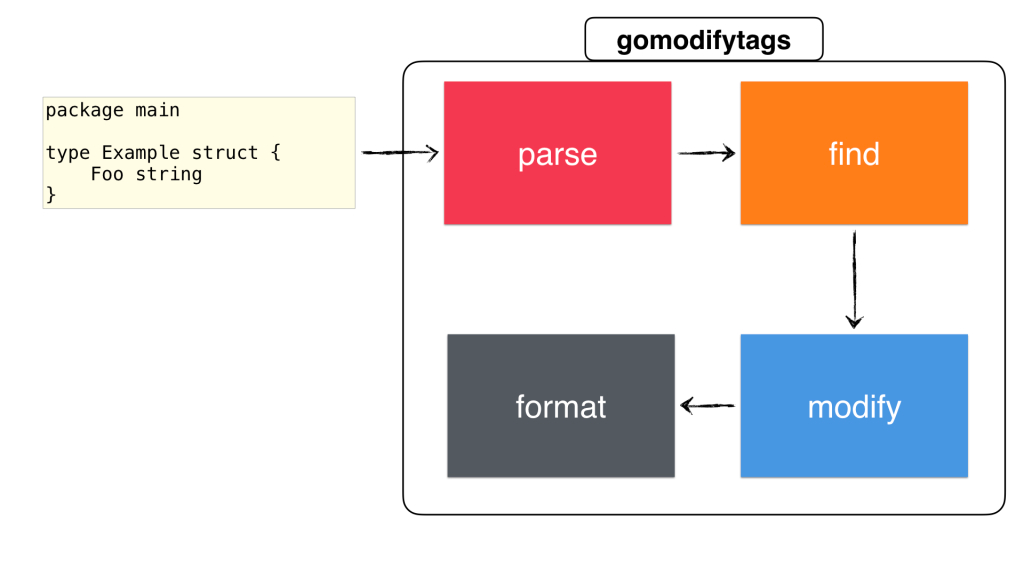
A while ago I've started to build a tool to make my life easier. It's called: gomodifytags. It automatically fills the struct tag fields based on the field names. Let me show you an example:
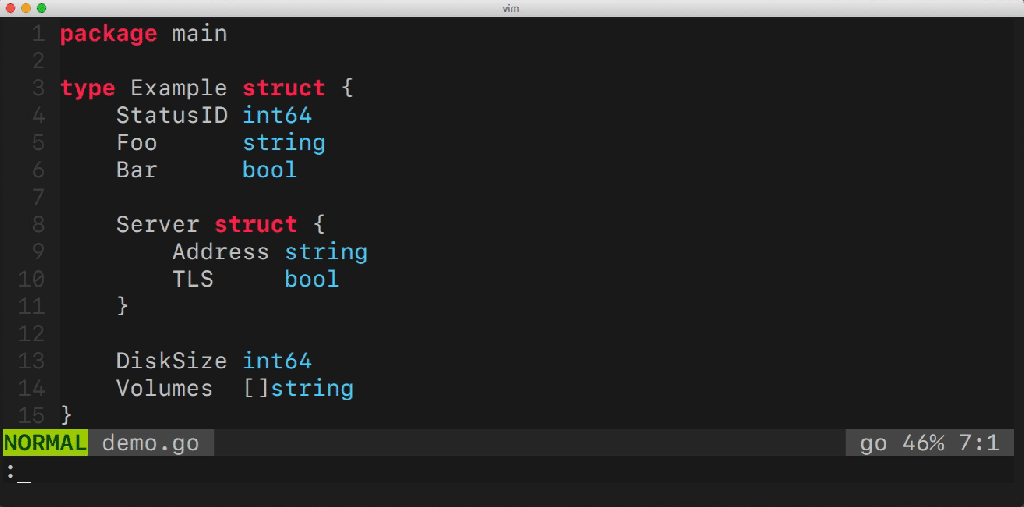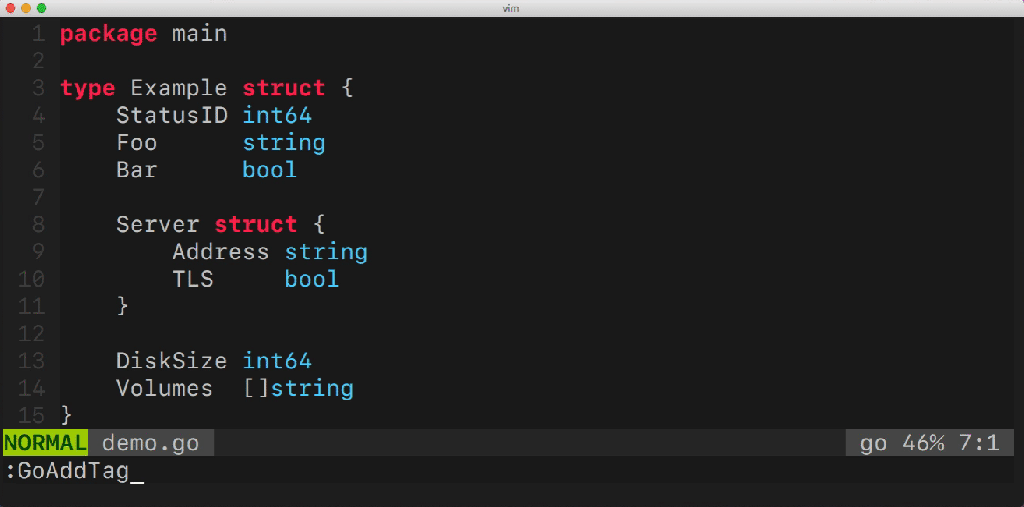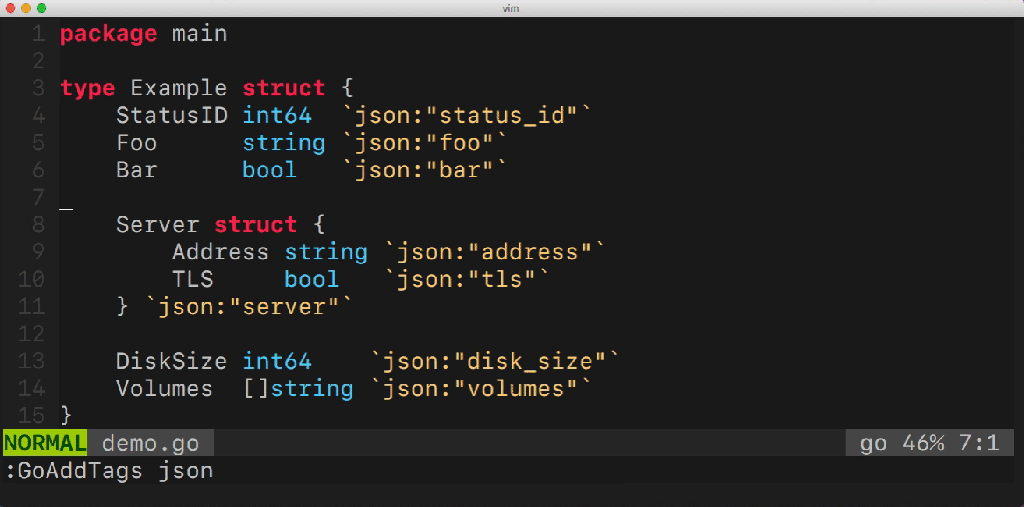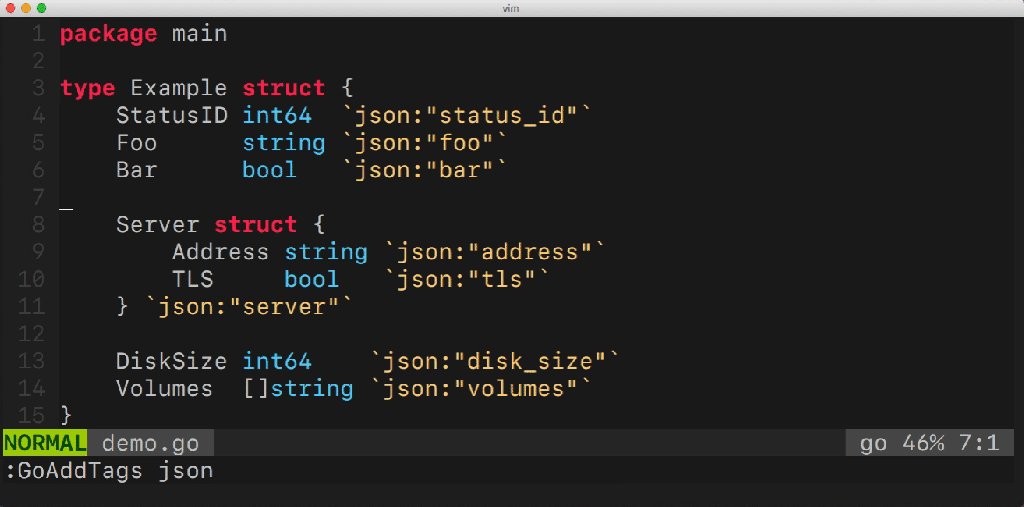
Having a tool like this makes it easy to manage multiple fields of a struct. The tool is also able to add&remove tags, manage tag options (such as omitempty), define the transformation rule (snake_case, camelCase, etc..) and much more. But how does this tool work? What Go packages does it use under the hood? There are so many questions that need to be answered.
This is a very lengthy blog post that explains every single detail of how to write such a tool and how to build it. It contains many unique details, tips & tricks and unknown Go bits.
Grab a coffee ☕️ and let's deep dive into it!
First, let me lay out what the tool needs to do:
- It needs to read the source file, understand and be able to parse the Go file
- It needs to find the relevant struct
- After finding the struct, it needs to be able to get the field names
- It needs to update the struct tags based on the field names (according to the transform rule, i.e: snake_case)
- It needs to be able to update the file with those changes or able to output the changes in a consumable way
Let's start by looking at what a struct tag definition is first and from there build up the tool along the way as we learn all the pieces and how they fit together.

A struct's tag value (the content, i.e: json:"foo") is not a part of the official spec, however, there is an unofficial spec defined by the reflect package that defines it in a format that is used also by stdlib packages (such as _encoding/_json). It is defined via the reflect.StructTag type:

The definition is not easy to understand as it's very dense. Let's try to decompose it:

- A struct tag is a string literal (because it has the string type)
- Key is an unquoted string literal
- Value is a quoted string literal
- Key and value are separated by a colon
(:). A key together with a value, separated by the colon is called a "key value pair" - A struct tag can contain multiple key value pairs (optional). The key-value pairs are separated by a space.
- Not part of the definition is the options setting. Packages like encoding/json read the value as a comma-separated list. Anything after the first comma is part of the options,** i.e: "foo,omitempty,string"**. Here the value has a name called "foo" and options ["omitempty", "string"]
- Because the struct tag is a string literal,** it needs to be quoted** either with a double quote or backtick. Because the value has to be quoted as well we always use backticks.
To recap all these rules:
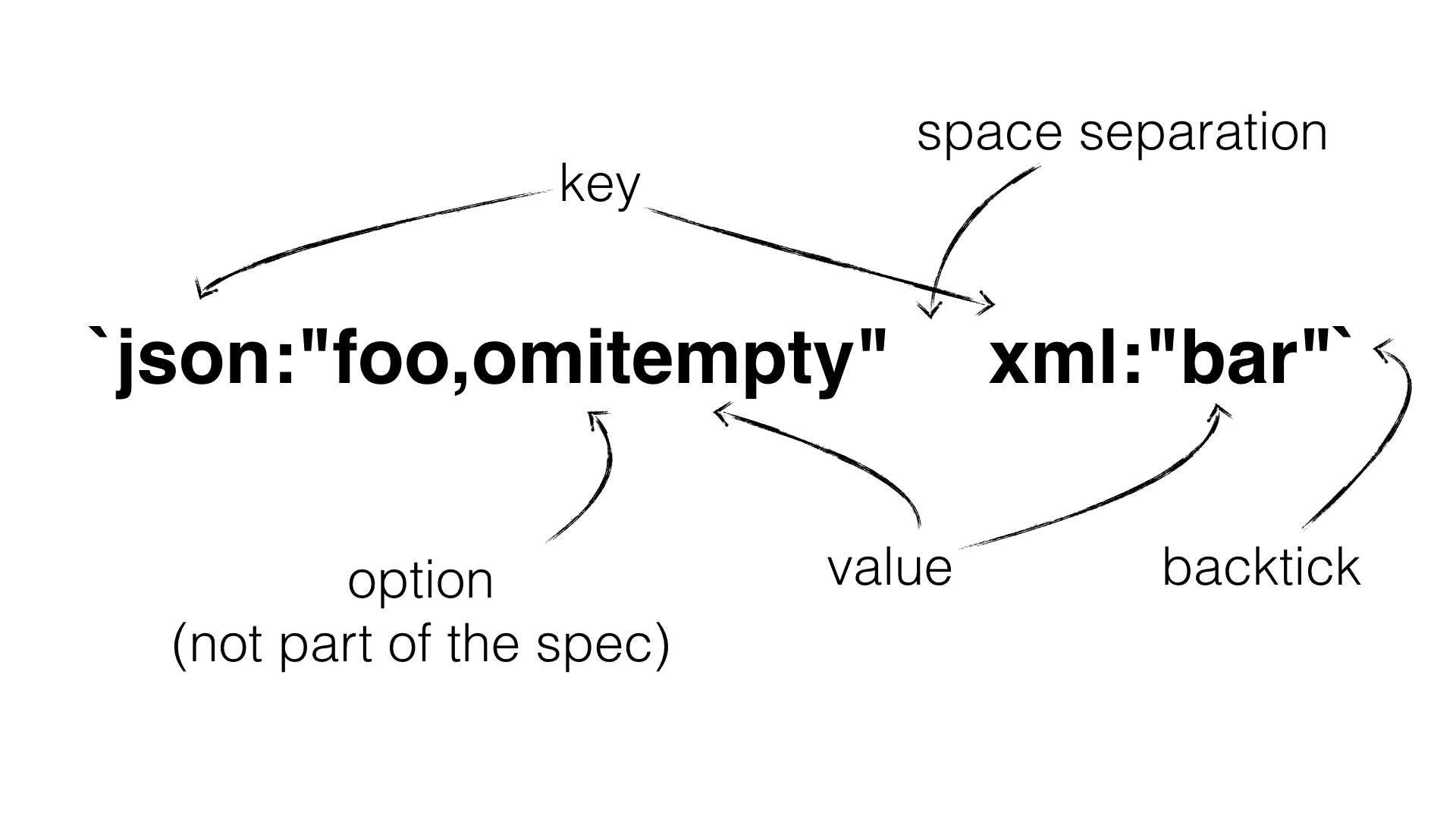
Now that we know what a struct tag is, we can easily modify it according to our needs. The question is now how can we parse it in a way that allows us to modify it easily?Luckily, the reflect.StructTag also contains a method that allows us to parse it and return the values for a given key. Below is an example that shows:
package main
import (
"fmt"
"reflect"
)
func main() {
tag := reflect.StructTag(`species:"gopher" color:"blue"`)
fmt.Println(tag.Get("color"), tag.Get("species"))
}
Prints:
blue gopher
If a key doesn't exist it returns an empty string.
This is very helpful, however, it has some caveats that make it not suitable for us as we need more flexibility. These are:
- It can't detect if the tag is malformed (i.e: key is quoted, value is unquoted, etc...)
- It doesn't know the semantics of an option
- It doesn't have a way to iterate over existing tags or return them. We have to know upfront which tags we want to modify. What if don't know the name?
- Modifying existing tags is not possible.
- We can't construct new struct tags from scratch.
To improve this I wrote a custom Go package that fixes all the problems above and provides an API that makes it easy to change every aspect of a struct tag.
The package is called structtag and can be fetched from github.com/fatih/structtag. This package allows us to parse and modify tags in a neat way. Below is a fully working example, copy/paste and try it yourself:
package main
import (
"fmt"
"github.com/fatih/structtag"
)
func main() {
tag := `json:"foo,omitempty,string" xml:"foo"`
// parse the tag
tags, err := structtag.Parse(string(tag))
if err != nil {
panic(err)
}
// iterate over all tags
for _, t := range tags.Tags() {
fmt.Printf("tag: %+v\n", t)
}
// get a single tag
jsonTag, err := tags.Get("json")
if err != nil {
panic(err)
}
// change existing tag
jsonTag.Name = "foo_bar"
jsonTag.Options = nil
tags.Set(jsonTag)
// add new tag
tags.Set(&structtag.Tag{
Key: "hcl",
Name: "foo",
Options: []string{"squash"},
})
// print the tags
fmt.Println(tags) // Output: json:"foo_bar" xml:"foo" hcl:"foo,squash"
}
Now that we know how to parse a struct tag, modify it or create a new one, it's time to modify a valid Go source file. In the example above the tag was already there, but how do we get the tag from an existing Go struct?
Short answer: via AST. An AST (Abstract Syntax Tree) allows us to retrieve every single identifier (node) from a source code. Below you can see the AST (simplified) of a struct type:
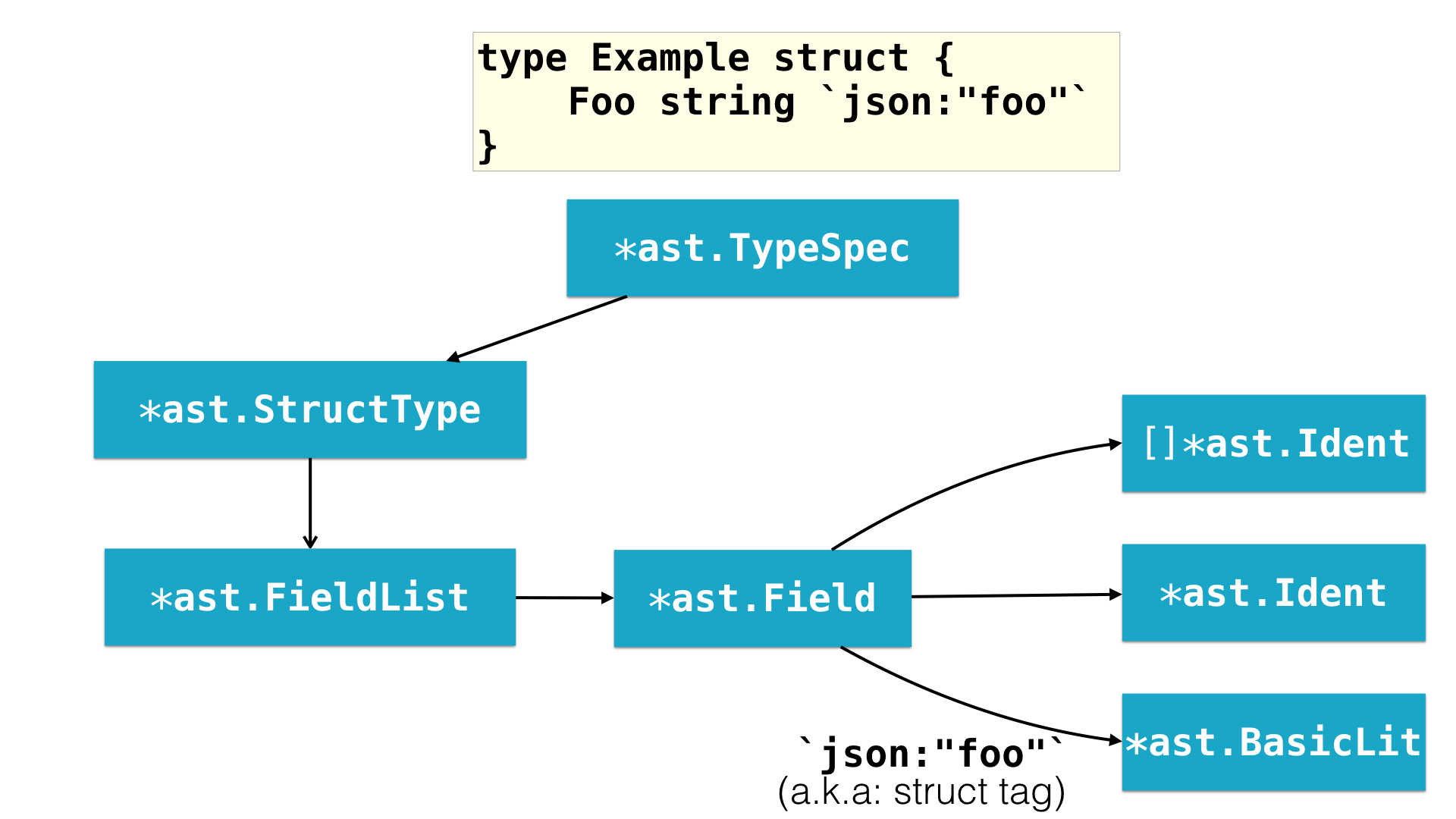
In this tree, we can retrieve and manipulate each identifier, each string, each brace, etc.. Each of these is represented by an AST node. For example, we could change the field name from "Foo" to "Bar" by replacing the node that represents it. The same logic applies to the struct tag.
To obtain a Go AST we need to parse the source file and transform it into an AST. Actually, this both is handled by a single step.
To do that we're going to use the go/parser package to parse the file to obtain the AST (of the whole file) and then use the go/ast package to walk down the tree (we could do it manually as well, but that's the topic of another blog post). Below you can see a fully working example:
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
)
func main() {
src := `package main
type Example struct {
Foo string` + " `json:\"foo\"` }"
fset := token.NewFileSet()
file, err := parser.ParseFile(fset, "demo", src, parser.ParseComments)
if err != nil {
panic(err)
}
ast.Inspect(file, func(x ast.Node) bool {
s, ok := x.(*ast.StructType)
if !ok {
return true
}
for _, field := range s.Fields.List {
fmt.Printf("Field: %s\n", field.Names[0].Name)
fmt.Printf("Tag: %s\n", field.Tag.Value)
}
return false
})
}
This outputs:
Field: Foo
Tag: `json:"foo"`
The code does the following:
- We define an example valid Go package with just a single struct
- We use the go/parser package to parse this string. The parser package is also able to read a file (or a whole package) from disk.
- After we parse it, we walk our node (assigned to the variable file) and look for the AST node defined by *ast.StructType (see the AST image for reference). Walking the tree is done via the
ast.Inspect()function. It walks all nodes until it receives the false value. This is very handy as it doesn't require to know each node. - We print the struct's field name and the struct tag.
We're able to do two important things now, first, we know how to parse a Go source file and retrieve the struct tag (via go/parser). Second, we know how to parse a Go struct tag and modify it for our needs (via github.com/fatih/structtag).
Now that we have these, we can start building our tool (named as gomodifytags) by using these two important pieces. The tool should do the followings in order
- Fetch the configuration that tells us which struct to modify
- Find and modify the struct based on the configuration
- Output the result
Because gomodifytags is going to be executed mainly by editors, we're going to pass the configuration via CLI flags. Step two contains multiple steps, such as parsing the file, finding the correct struct and then modifying the struct (by modifying the AST). Lastly, we're going to output the results, either in its original Go source file or in some sort of custom protocol (such as JSON, more on this later).
Below is the simplified main function of gomodifytags:

Let us start explaining each step in more detail. To keep it simple I'm going to try to explain the important bits in a distilled form. Everything is the same though and once you finish this blog post, you'll be able to read the whole source code without any guidance (you'll find all the resources at the end of the guide)
Let us start with the first step, on how to get the configuration. Below is our config that holds all the necessary information
type config struct {
// first section - input & output
file string
modified io.Reader
output string
write bool
// second section - struct selection
offset int
structName string
line string
start, end int
// third section - struct modification
remove []string
add []string
override bool
transform string
sort bool
clear bool
addOpts []string
removeOpts []string
clearOpt bool
}
It's separated into three main sections:
The first sections contain the setting on how and which file to read. This can be a filename from the local filesystem or directly from stdin (which is used mainly within from editors). It also sets how to output the result (go source file or JSON) and whether we should overwrite the file instead of outputting it to stdout
The second section defines on how to select a struct and its fields.
There are multiple ways to do it. We can either define it via it's offset
(cursor position), the struct name, a single line (which just selects the
field) or a range of lines. In the end, we always need to get the start/end
lines. For example below you see an example where we select the struct with its
name and then extract the start and end lines so we can pick up the correct
fields:
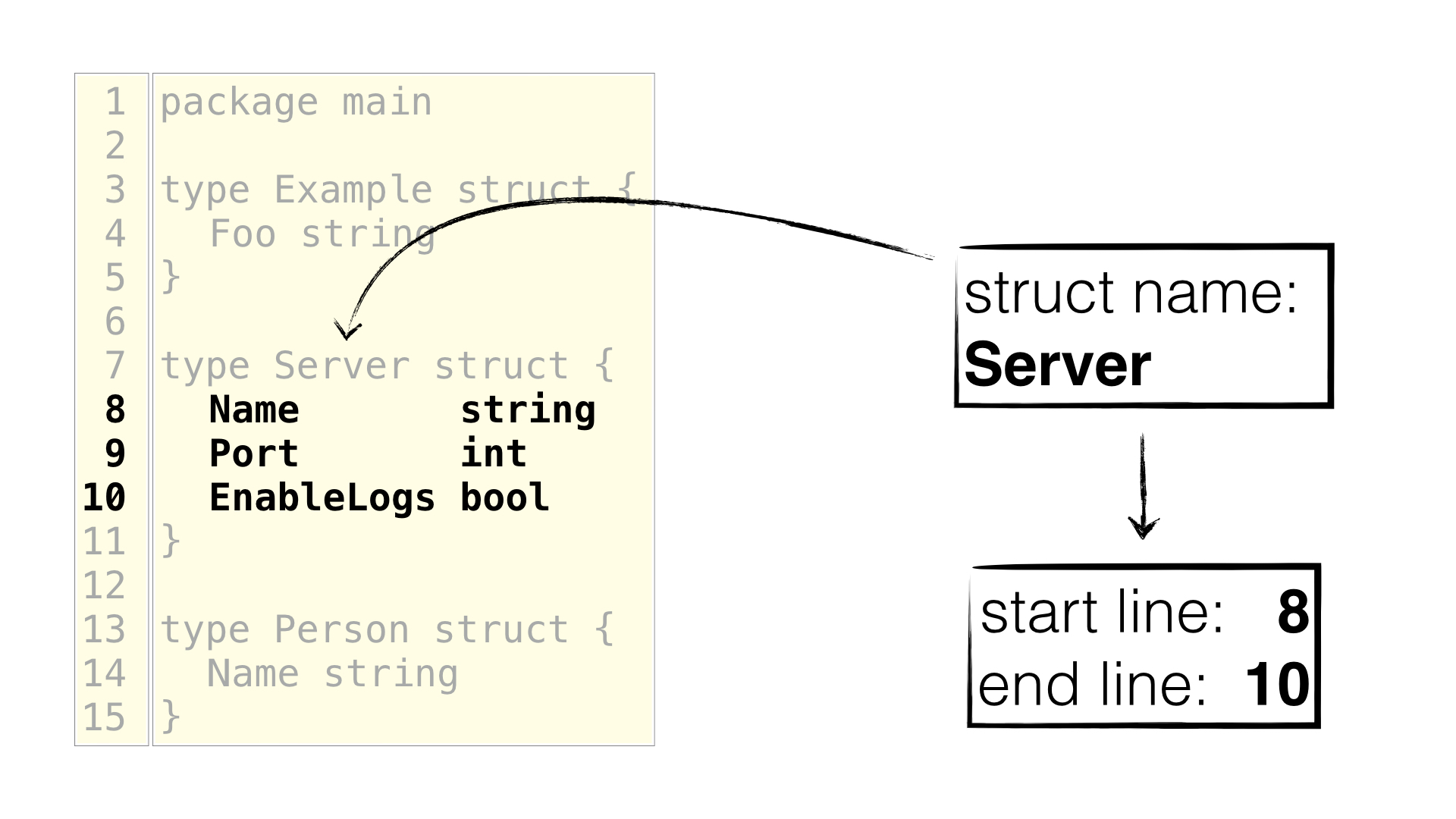
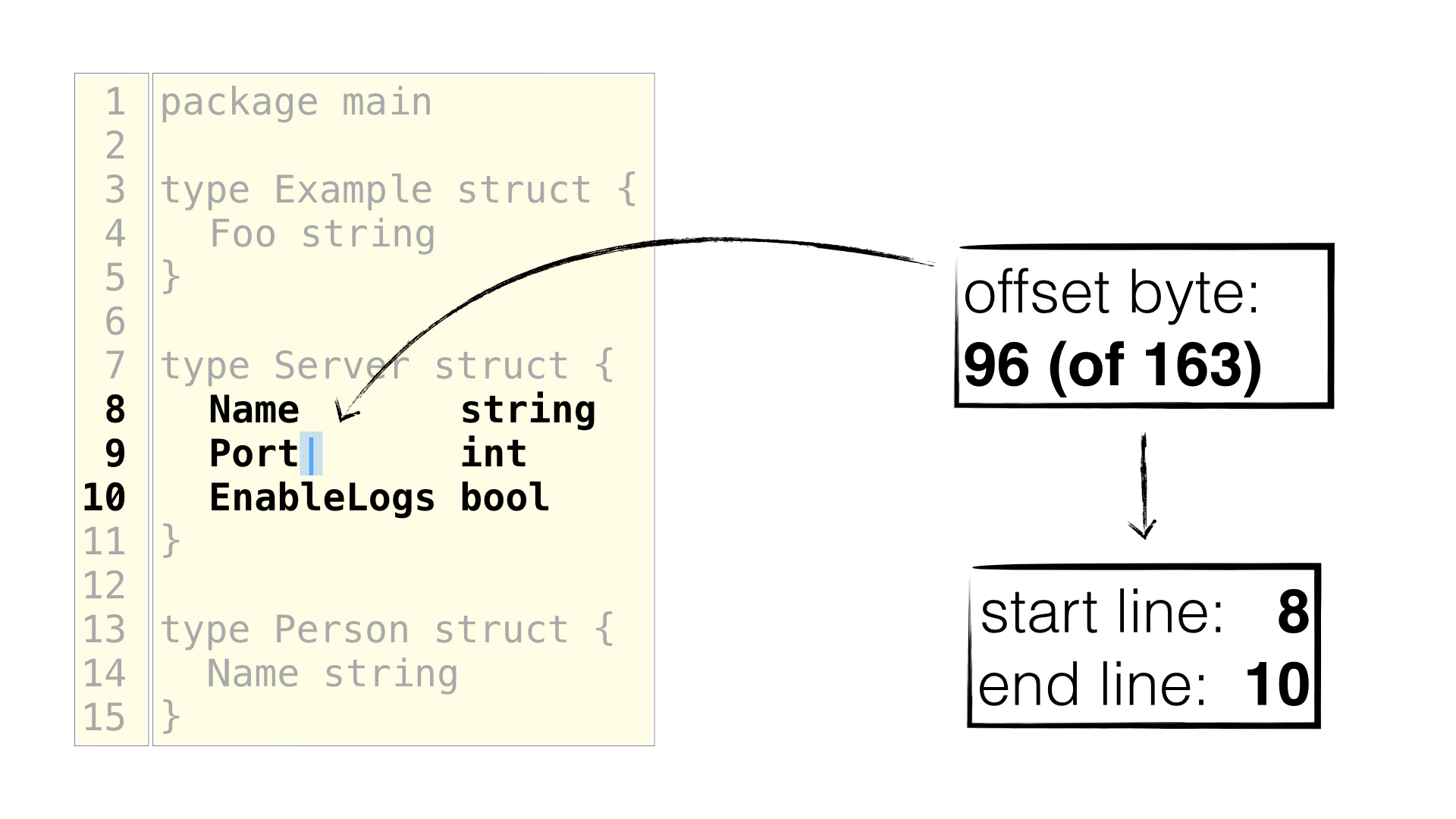
Whereas for an editor it's best to use the byte offset. For example below
you can see that our cursor is just after the "Port" field name, from there
we can easily get the start/end lines:
The third section in the config is actually a one-to-one mapping to ourstructtag package. It basically allows us to pass the configuration to the
structtag package after reading the fields. As you know the structtag package
allows us to parse a struct tag and modify it in various parts. However, it
doesn't overwrite or update the struct field.
How do we get the configuration though? We simply use the flag package and then create a flag for each of the fields in the configuration and then assign them. As an example:
flagFile := flag.String("file", "", "Filename to be parsed")
cfg := &config{
file: *flagFile,
}
We do the same for each of the fields in the configuration. For the full list check out the current master of gomodifytag for flag definitions
Once we have the configuration we do some basic validations:
func main() {
cfg := config{ ... }
err := cfg.validate()
if err != nil {
log.Fatalln(err)
}
// continue parsing
}
// validate validates whether the config is valid or not
func (c *config) validate() error {
if c.file == "" {
return errors.New("no file is passed")
}
if c.line == "" && c.offset == 0 && c.structName == "" {
return errors.New("-line, -offset or -struct is not passed")
}
if c.line != "" && c.offset != 0 ||
c.line != "" && c.structName != "" ||
c.offset != 0 && c.structName != "" {
return errors.New("-line, -offset or -struct cannot be used together. pick one")
}
if (c.add == nil || len(c.add) == 0) &&
(c.addOptions == nil || len(c.addOptions) == 0) &&
!c.clear &&
!c.clearOption &&
(c.removeOptions == nil || len(c.removeOptions) == 0) &&
(c.remove == nil || len(c.remove) == 0) {
return errors.New("one of " +
"[-add-tags, -add-options, -remove-tags, -remove-options, -clear-tags, -clear-options]" +
" should be defined")
}
return nil
}
Having the validation part in one single function makes it easy to test it.
Now that we know how to get the configuration and validate it, let's move on to
parsing the file:
We already talked about how to parse a file in the beginning. Here parsing is a method of the config struct. Actually, all the methods are part of the config struct:
func main() {
cfg := config{}
node, err := cfg.parse()
if err != nil {
return err
}
// continue find struct selection ...
}
func (c *config) parse() (ast.Node, error) {
c.fset = token.NewFileSet()
var contents interface{}
if c.modified != nil {
archive, err := buildutil.ParseOverlayArchive(c.modified)
if err != nil {
return nil, fmt.Errorf("failed to parse -modified archive: %v", err)
}
fc, ok := archive[c.file]
if !ok {
return nil, fmt.Errorf("couldn't find %s in archive", c.file)
}
contents = fc
}
return parser.ParseFile(c.fset, c.file, contents, parser.ParseComments)
}
The parse function does only one thing. Parse the source code and return an ast.Node. It's very simple if we just pass a file, in that case, we use the parser.ParseFile() function. One thing to note is token.NewFileSet() which creates a type *token.FileSet. We store this in c.fset but also pass to the parser.ParseFile() function. Why?
Because the fileset is used to store each node's position information independently for each file. This will be later very helpful to get the exact position of an ast.Node (note that the ast.Node uses a compact position information called token.Pos. To get more information it needs to be decoded via the token.FileSet.Position() function to get a token.Position, which contains more information)
Let's move on. It gets more interesting if pass the source file via stdin. The config.modified field is an **io.Reader** for easy testing, but in reality, we pass stdin. How do we detect if we want to read from stdin?
We ask the user if they want to pass content via stdin. The user of the tool, in that case, needs to pass the --modified flag (this is a boolean flag). If the user passes it we simply assign stdin to c.modified:
flagModified = flag.Bool("modified", false,
"read an archive of modified files from standard input")
if *flagModified {
cfg.modified = os.Stdin
}
And if you check again the config.parse() function above, you see we check whether the .modified field is assigned to. Because stdin is an arbitrary stream of data we need to be able it to parse according to a given protocol. In this case, we assume the archive consists the followings:
- The file name, followed by a newline
- The (decimal) file size, followed by a newline
- The contents of the file
Because we know the file size, we're able to parse the content of the file without any issues. Anything larger than the given file size we just stop parsing.
This approach is used by several other tools as well (such as guru, gogetdoc, etc..) and is very useful especially for editors. Because this allows editors to pass their modified file content without saving to the file system. Hence the name "modified".
Now that we have our node let's continue with "finding the struct" step:
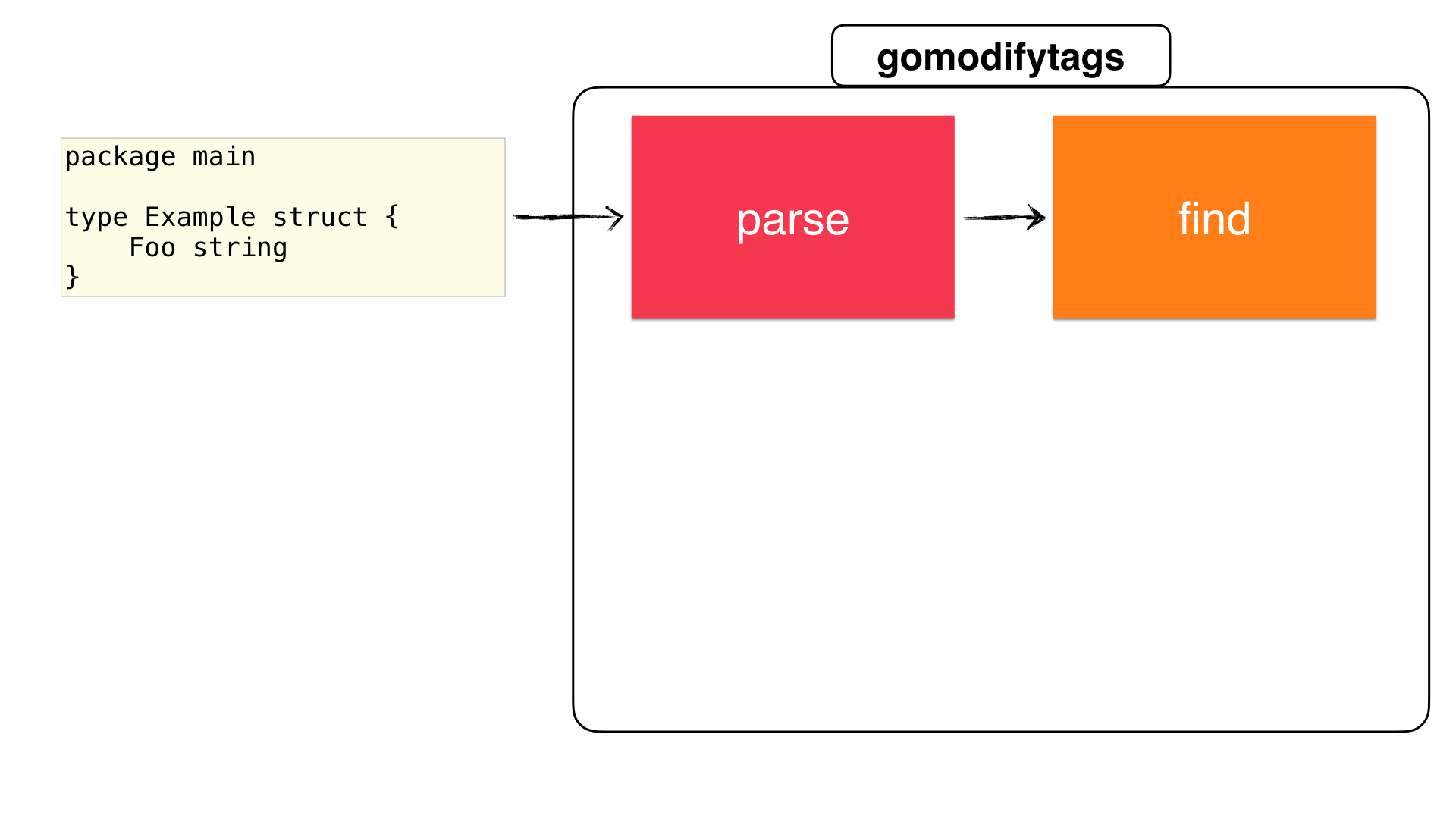
In our main function we're going to call the findSelection() function with the ast.Node we parsed from the previous step:
func main() {
// ... parse file and get ast.Node
start, end, err := cfg.findSelection(node)
if err != nil {
return err
}
// continue rewriting the node with the start&end position
}
The cfg.findSelection() function returns the start and end positions of a struct based on the configuration and how we want to select a struct. It iterates for the given node and then returns the start/end positions (as explained above in the configuration section):
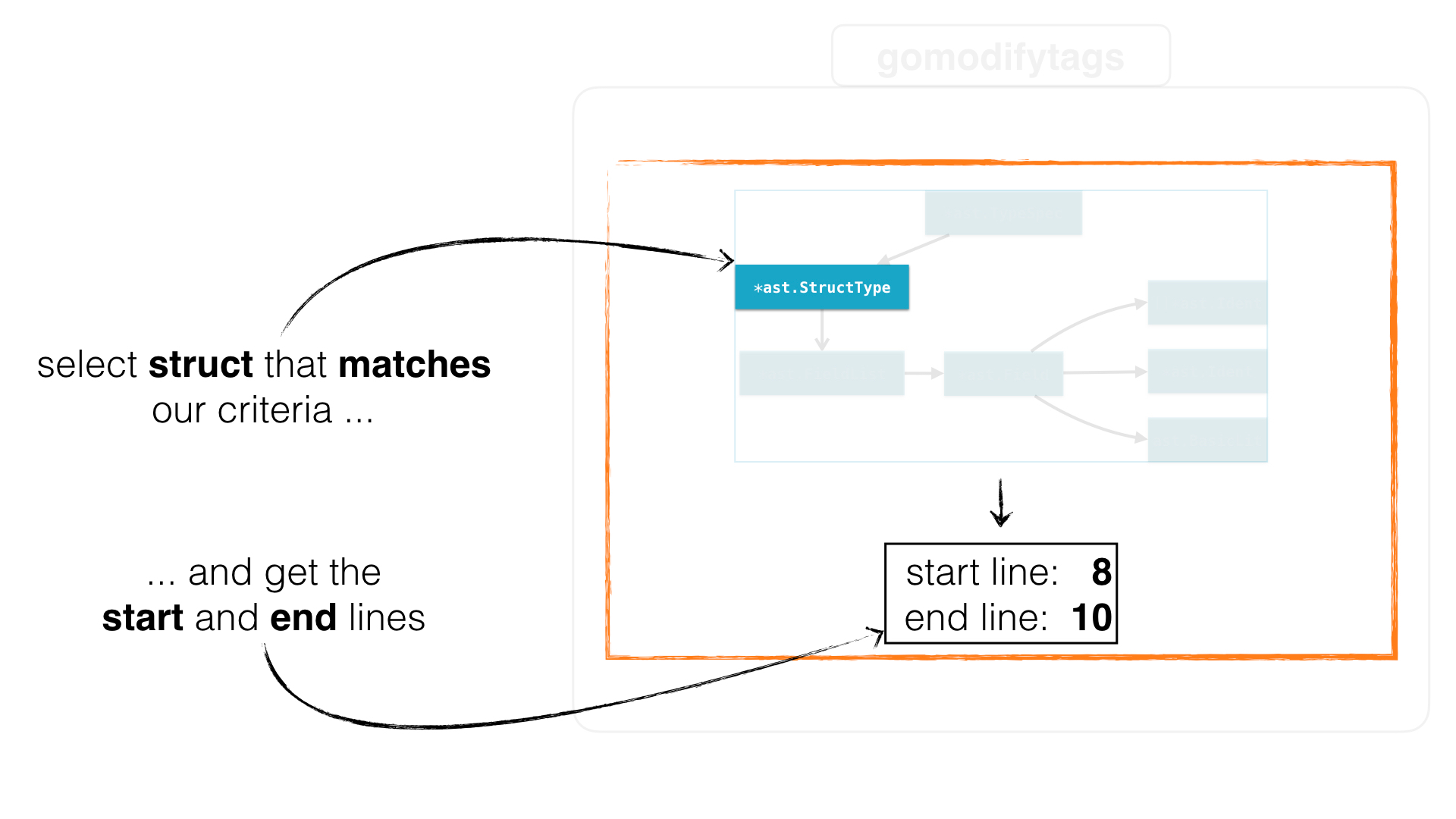
But how is this done? Remember that there are three modes. These are line selection, offset and** struct name**:
// findSelection returns the start and end position of the fields that are
// suspect to change. It depends on the line, struct or offset selection.
func (c *config) findSelection(node ast.Node) (int, int, error) {
if c.line != "" {
return c.lineSelection(node)
} else if c.offset != 0 {
return c.offsetSelection(node)
} else if c.structName != "" {
return c.structSelection(node)
} else {
return 0, 0, errors.New("-line, -offset or -struct is not passed")
}
}
The line selection part is the easiest part. Here we just return the flag value itself. So if the user passed the flag "--line 3,50", the function returns (3, 50, nil). All it does is to split the flag value and convert them to integer (and also validating by doing it):
func (c *config) lineSelection(file ast.Node) (int, int, error) {
var err error
splitted := strings.Split(c.line, ",")
start, err := strconv.Atoi(splitted[0])
if err != nil {
return 0, 0, err
}
end := start
if len(splitted) == 2 {
end, err = strconv.Atoi(splitted[1])
if err != nil {
return 0, 0, err
}
}
if start > end {
return 0, 0, errors.New("wrong range. start line cannot be larger than end line")
}
return start, end, nil
}
This mode is used by editors when you select a set of lines and highlight them.
The offset and struct name selections require a little more work. For those, we need to collect all given structs first so we can compute the offset position or search for the struct name. For that we have a function that first collects all structs:
// collectStructs collects and maps structType nodes to their positions
func collectStructs(node ast.Node) map[token.Pos]*structType {
structs := make(map[token.Pos]*structType, 0)
collectStructs := func(n ast.Node) bool {
t, ok := n.(*ast.TypeSpec)
if !ok {
return true
}
if t.Type == nil {
return true
}
structName := t.Name.Name
x, ok := t.Type.(*ast.StructType)
if !ok {
return true
}
structs[x.Pos()] = &structType{
name: structName,
node: x,
}
return true
}
ast.Inspect(node, collectStructs)
return structs
}
We use the ast.Inspect() function to walk down the AST and search for structs.
We search for *ast.TypeSpec first so we can obtain the struct name. Searching for *ast.StructType would yield us the struct itself, but not the name of it. That's why we have a custom structType type, which holds both the name and the struct node itself. This comes handy in various places. Because each struct's position is unique and there can't be different two structs on the same position, we use the position as the key for the map.
So now that we have all structs, we can finally return the start and end positions of a struct for the offset and struct name modes. For the offset position we check whether the offset is between a given struct:
func (c *config) offsetSelection(file ast.Node) (int, int, error) {
structs := collectStructs(file)
var encStruct *ast.StructType
for _, st := range structs {
structBegin := c.fset.Position(st.node.Pos()).Offset
structEnd := c.fset.Position(st.node.End()).Offset
if structBegin <= c.offset && c.offset <= structEnd {
encStruct = st.node
break
}
}
if encStruct == nil {
return 0, 0, errors.New("offset is not inside a struct")
}
// offset mode selects all fields
start := c.fset.Position(encStruct.Pos()).Line
end := c.fset.Position(encStruct.End()).Line
return start, end, nil
}
We use collectStructs() to collect all structs and then iterate here. Remember that we stored the initial token.FileSet we used to parse the file?
This is now used to get the offset information from each individual struct node (we decode it to a token.Position which provides us the .Offset field). All we do is a simple check and iterate until we found our struct (named as encStruct here):
for _, st := range structs {
structBegin := c.fset.Position(st.node.Pos()).Offset
structEnd := c.fset.Position(st.node.End()).Offset
if structBegin <= c.offset && c.offset <= structEnd {
encStruct = st.node
break
}
}
With this information, we can extract the start and end position of our found struct:
start := c.fset.Position(encStruct.Pos()).Line
end := c.fset.Position(encStruct.End()).Line
The same logic applies to the struct name selection as well. All we do is, instead of checking whether the offset is inside a given struct, we try to check for the struct name until we found a struct with the given name:
func (c *config) structSelection(file ast.Node) (int, int, error) {
// ...
for _, st := range structs {
if st.name == c.structName {
encStruct = st.node
}
}
// ...
}
Now that we have our start and end positions, we can finally continue with the third step: modifying the struct fields:
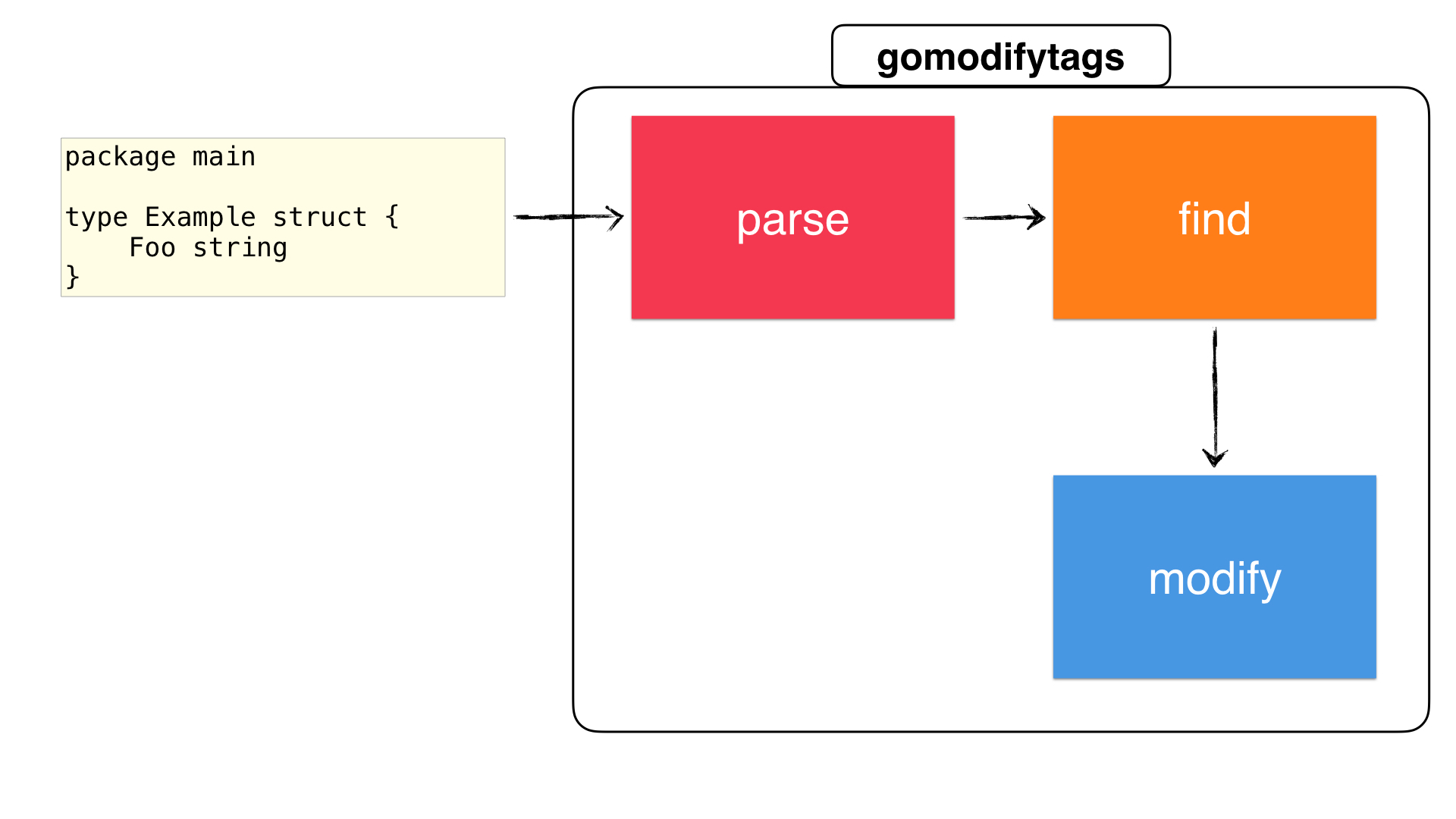
In our main function we're going to call the cfg.rewrite() function with the node we parsed from the previous step:
func main() {
// ... find start and end position of the struct to be modified
rewrittenNode, errs := cfg.rewrite(node, start, end)
if errs != nil {
if _, ok := errs.(*rewriteErrors); !ok {
return errs
}
}
// continue outputting the rewritten node
}
This is the core of the tool. In the rewrite function we're rewriting the fields of all structs between the start and end positions. Before we deep dive into it, here is an overview of the function:
// rewrite rewrites the node for structs between the start and end
// positions and returns the rewritten node
func (c *config) rewrite(node ast.Node, start, end int) (ast.Node, error) {
errs := &rewriteErrors{errs: make([]error, 0)}
rewriteFunc := func(n ast.Node) bool {
// rewrite the node ...
}
if len(errs.errs) == 0 {
return node, nil
}
ast.Inspect(node, rewriteFunc)
return node, errs
}
As you see, we're using again ast.Inspect() to walk down the tree for the given node. We're rewriting each field's tags inside the rewriteFunc function (more on this below).
Because the function passed to ast.Inspect() doesn't return an error, we're going to create a map of errors (defined with the errs variable) and then collect errors while we walk down the tree and process each individual field. Let's talk about the internals of rewriteFunc:
rewriteFunc := func(n ast.Node) bool {
x, ok := n.(*ast.StructType)
if !ok {
return true
}
for _, f := range x.Fields.List {
line := c.fset.Position(f.Pos()).Line
if !(start <= line && line <= end) {
continue
}
if f.Tag == nil {
f.Tag = &ast.BasicLit{}
}
fieldName := ""
if len(f.Names) != 0 {
fieldName = f.Names[0].Name
}
// anonymous field
if f.Names == nil {
ident, ok := f.Type.(*ast.Ident)
if !ok {
continue
}
fieldName = ident.Name
}
res, err := c.process(fieldName, f.Tag.Value)
if err != nil {
errs.Append(fmt.Errorf("%s:%d:%d:%s",
c.fset.Position(f.Pos()).Filename,
c.fset.Position(f.Pos()).Line,
c.fset.Position(f.Pos()).Column,
err))
continue
}
f.Tag.Value = res
}
return true
}
Remember this function is called for every single node in the AST tree. Because of that, we're looking only for nodes of type *ast.StructType. Once we have it, we start iterating over the struct fields.
Here we use our beloved start and end variables. This defines whether we want to modify the field or not. If the field position is between start-end we continue, otherwise we don't care about it:
if !(start <= line && line <= end) {
continue // skip processing the field
}
Next, we check if there is a tag or not. We initialize the tag field if it's empty (a.k.a nil) with an empty tag. This is helpful later in the cfg.process() function to avoid panicing:
if f.Tag == nil {
f.Tag = &ast.BasicLit{}
}
Now let me explain an interesting bit before we continue. gomodifytags tries to get the field name of the field and processes it. However what if it's an anonymous field? :
type Bar string
type Foo struct {
Bar //this is an anonymous field
}
In this case, because there is no field name, we're trying to assert the field name from the type name:
// if there is a field name use it
fieldName := ""
if len(f.Names) != 0 {
fieldName = f.Names[0].Name
}
// if there is no field name, get it from type's name
if f.Names == nil {
ident, ok := f.Type.(*ast.Ident)
if !ok {
continue
}
fieldName = ident.Name
}
Once we have the field name and the tag value, we can start processing the field. The cfg.process() function is responsible for processing the field with the given field name and the tag value (if any). It returns the processed result (in our case the struct tag formatting) back, which we use then to override the existing tag value:
res, err := c.process(fieldName, f.Tag.Value)
if err != nil {
errs.Append(fmt.Errorf("%s:%d:%d:%s",
c.fset.Position(f.Pos()).Filename,
c.fset.Position(f.Pos()).Line,
c.fset.Position(f.Pos()).Column,
err))
continue
}
// rewrite the field with the new result,i.e: json:"foo"
f.Tag.Value = res
In fact, if you remember the structtag, it returns the String() representation of the tags instance. We're using the various methods of the structtag package to modify the struct according to our needs before we returning the final representation of the tag. Here is a simplified overview of it:
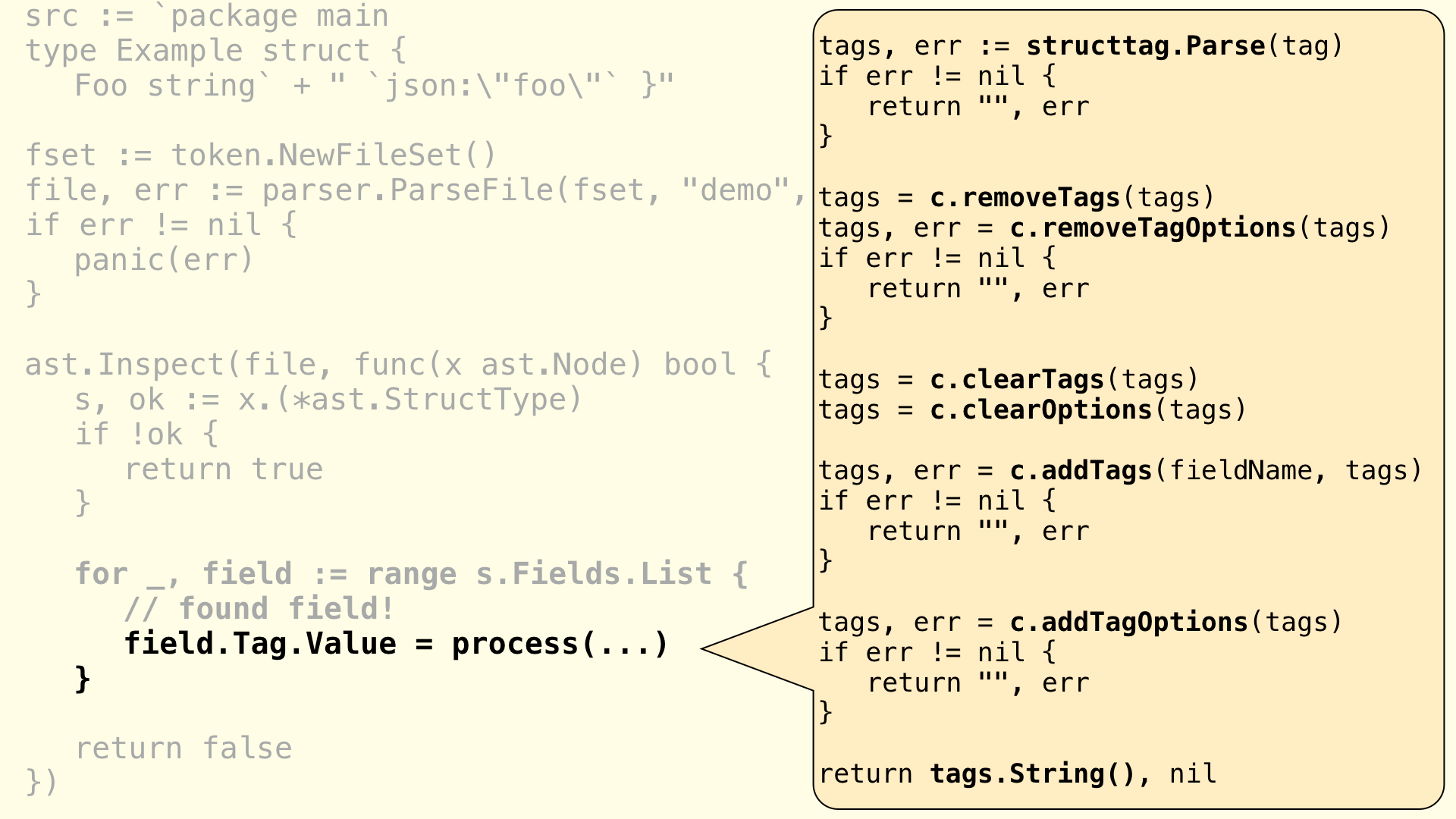
For example, let's expand the removeTags() functions inside process(). This function is uses the following configuration that creates an array of tags (key names) to be deleted:
flagRemoveTags = flag.String("remove-tags", "", "Remove tags for the comma separated list of keys")
if *flagRemoveTags != "" {
cfg.remove = strings.Split(*flagRemoveTags, ",")
}
Inside removeTags() we check if anyone has used --remove-tags. In that case, we use structtag's tags.Delete() method to remove the tags:
func (c *config) removeTags(tags *structtag.Tags) *structtag.Tags {
if c.remove == nil || len(c.remove) == 0 {
return tags
}
tags.Delete(c.remove...)
return tags
}
The same logic applies to all individual functions inside cfg.Process().
Now that we have a rewritten node, let's talk about the final piece. Outputting and formatting the result:
In our main function we're going to call the cfg.format() function with the node we rewrote from the previous step:
func main() {
// ... rewrite the node
out, err := cfg.format(rewrittenNode, errs)
if err != nil {
return err
}
fmt.Println(out)
}
One thing you notice is that we output to stdout. This has many advantages. First, it allows anyone to dry run the tool and see the results. It doesn't change anything but allows the user of the tool to see an immediate result. Second, stdout is composable that you can redirect it to everywhere and can even use to overwrite the original tool.
Let's dive now into the format() function:
func (c *config) format(file ast.Node, rwErrs error) (string, error) {
switch c.output {
case "source":
// return Go source code
case "json":
// return a custom JSON output
default:
return "", fmt.Errorf("unknown output mode: %s", c.output)
}
}
We have two output modes.
The first one ("source") prints the ast.Node in Go format. This is the default option and is perfect if you're using it from the command line or just want to see the changes in your file.
The second option ("json") is more advanced and is specifically designed for other environments (especially for editors). It encodes the output based on the following struct:
type output struct {
Start int `json:"start"`
End int `json:"end"`
Lines []string `json:"lines"`
Errors []string `json:"errors,omitempty"`
}
An overview of an input to the tool with the corresponding output (without any errors) would be like:

Back to the format() function. As said earlier, there are two modes. The source mode uses the go/format package to format an AST back to a valid Go source. This package is also used by many other official tools, such as **gofmt**. Here it's how the "source" mode is implemented:
var buf bytes.Buffer
err := format.Node(&buf, c.fset, file)
if err != nil {
return "", err
}
if c.write {
err = ioutil.WriteFile(c.file, buf.Bytes(), 0)
if err != nil {
return "", err
}
}
return buf.String(), nil
The format package accepts an io.Writer and formats it. That's why we created an intermediate buffer (var buf bytes.Buffer) so we can use it also to overwrite the file when the user passes a -write flag. After the formatting, we're returning the string representation of the buffer, which contains the formatted Go source code.
The json mode is more interesting. Because we return a section of the source code, we need to return exactly how it looks like, this means comments included as well. The problem though is that using format.Node() to print a single struct is not able to print Go comments if they are lossy.
What are lossy comments? Check out this example :
type example struct {
foo int
// this is a lossy comment
bar int
}
Each field is of type *ast.Field. This struct has a *ast.Field.Comment field that contains the comment for that specific field.
But for the example above, to whom does it belong? Is it a part of foo or bar?
Because it's impossible to determine it, these comments are called loosely comments. Now the problem occurs if you print the struct above with the format.Node() function. When you print it, this is what you get (https://play.golang.org/p/peHsswF4JQ):
type example struct {
foo int
bar int
}
The problem is that lossy comments are part of the *ast.File and hold separated from the tree. And those are only printed when you print the whole file. So the workaround this is to print the whole file and then cut out the specific lines we want to return in the JSON output:
var buf bytes.Buffer
err := format.Node(&buf, c.fset, file)
if err != nil {
return "", err
}
var lines []string
scanner := bufio.NewScanner(bytes.NewBufferString(buf.String()))
for scanner.Scan() {
lines = append(lines, scanner.Text())
}
if c.start > len(lines) {
return "", errors.New("line selection is invalid")
}
out := &output{
Start: c.start,
End: c.end,
Lines: lines[c.start-1 : c.end], // cut out lines
}
o, err := json.MarshalIndent(out, "", " ")
if err != nil {
return "", err
}
return string(o), nil
This makes it sure that we print all comments.
That's it!
We successfully completed our tool and the following is our complete step by step diagram we used throughout the guide:
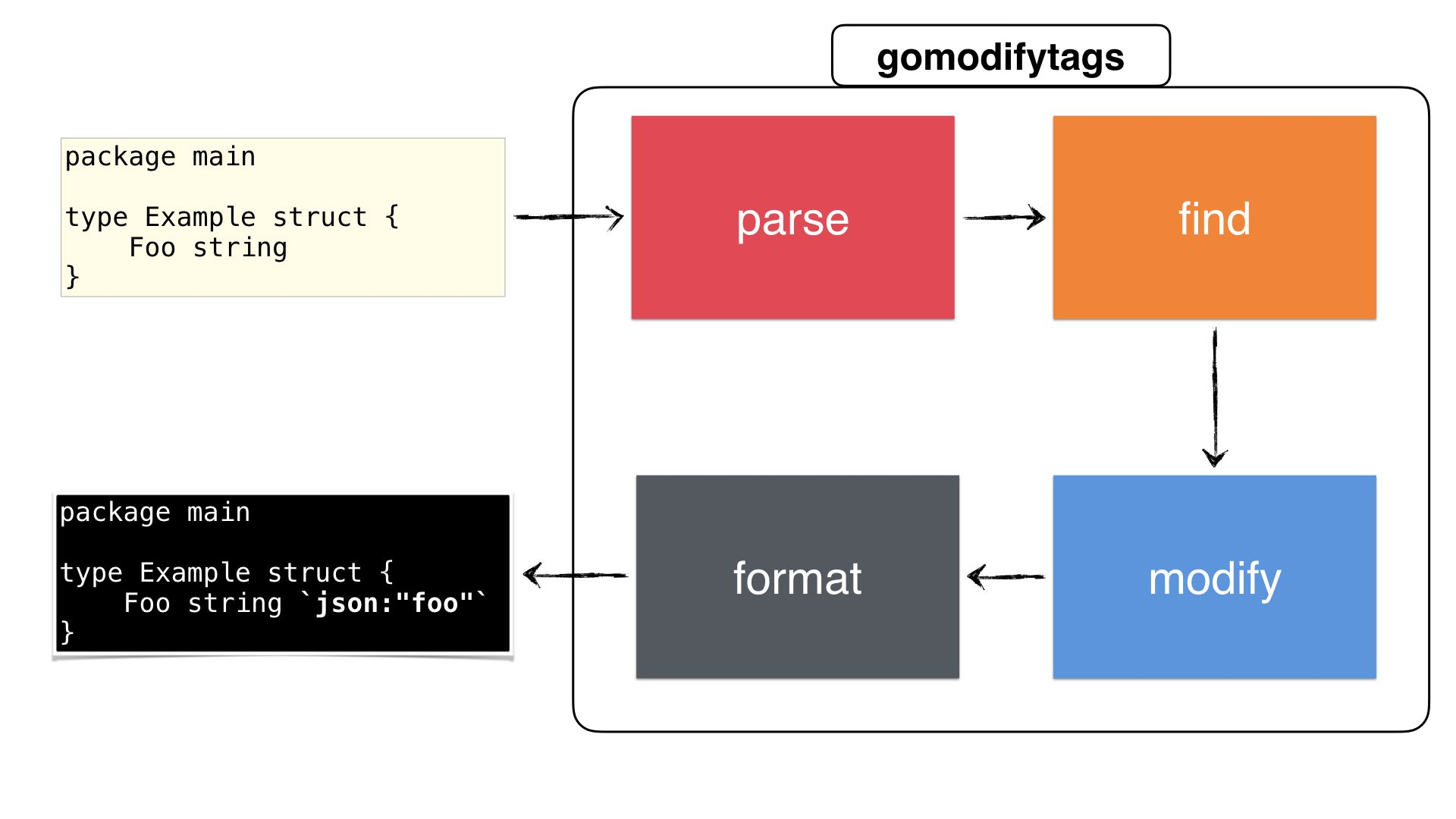
For a recap what we've done:
- We retrieve the configuration via the CLI flags
- We start to parse the file via the
go/parserpackage to obtain anast.Node. - After parsing the file, we're **searching **(walking down the tree) for the respective struct to get the start and end positions so we know which fields we need to modify
- Once we have the start & end position, we walk down the
ast.Nodeagain and rewrite each field that is between the start &end positions (by using the structtag package) - We then format the rewritten node, either in valid Go source code or in a custom JSON output for editors
After creating this tool I've received many great comments how this tool simplified their day to day work. Even though it looks like it's easily done, as you see, throughout the guide we have seen that there are many unique cases we need to take care of.
gomodifytags is now used by the following editor & plugins successfully for months and makes the life of thousands of developers more productive:
- vim-go
- atom
- vscode
- acme
If you're interested into the original source code, it can be found here:
I also gave a talk at Gophercon 2017, watch it for more details if you're interested:
Thanks for reading. Let me know if this guide inspired you to create a new Go tool from scratch.