Using go/analysis to write a custom linter

If you ask people why they're in love with Go, one of the answers is tooling. The reason is that it's very easy to write tooling, especially for the Go language itself. One of the strong areas is linting. If you're already using Go, you know and use some of the tools such as go vet, golint, staticcheck, etc..
All these tools are using under the hood go/{ast, packages, types, etc..} packages which enable us to parse and interpret any given Go code. However, there isn't a common framework that provides an easy and performant way to analyze Go code. If you use the packages above, you have to implement most of the cruft yourself (flag parsing, efficient walking over the AST, passing context/information around, etc..).
To improve the current situation and laid out a better base for future work, the Go author's introduced a new package: go/analysis.
The go/analysis package provides a common interface to implement checkers. A checker is an analysis that reports mistakes. The package is still in work in progress and things are changing quickly, so make sure to occasionally check for new updates.
In this blog post, we're going to write a custom linter (a.k.a checker) using the new go/analysis package. If you haven't used some of the tooling around parsing and checking Go source code (such as the go/parser and go/ast packages), please read first my previous blog post: The ultimate guide to writing a Go tool. This is required to understand the rest of the blog post.
Now, let's continue writing our custom linter!
Requirements of the custom linter
First let us define the requirements for our custom linter. This is going to be a very simple. Let us call our linter: addlint. The duty of this checker is to report us the usages of integer additions:
3 + 2
As an example, suppose we have the following simple main package:
package main
import "fmt"
func main() {
sum := 3 + 2
fmt.Printf("Sum: %d\n", sum)
}
If we run addlint on this file, it should report us the following:
$ addlint foo.go
/Users/fatih/foo.go:6:9: integer addition found: '3 + 2'
It should also work on packages, just like how any other of the current Go tools are working:
$ addlint github.com/my/repo
/Users/fatih/repo/foo.go:6:9: integer addition found: '3 + 2'
Implementing it the old style
Before we dive into using go/analysis, let us start implementing our custom checker by using the traditional, low-level packages such as go/parser, go/ast, etc.. We need to use these packages nevertheless, but it'll give us a way to understand what go/analysis improves.
We need to understand first what 3 + 2 means. This is a binary expression in Go. A binary expression can be represented by the AST node type *ast.BinaryExpr. For example, a simple 3 + 2 binary expression can be written as:
expr := &ast.BinaryExpr{
X: &ast.BasicLit{
Value: "3",
Kind: token.INT,
},
Op: token.ADD,
Y: &ast.BasicLit{
Value: "2",
Kind: token.INT,
},
}
To depict it as a graph:
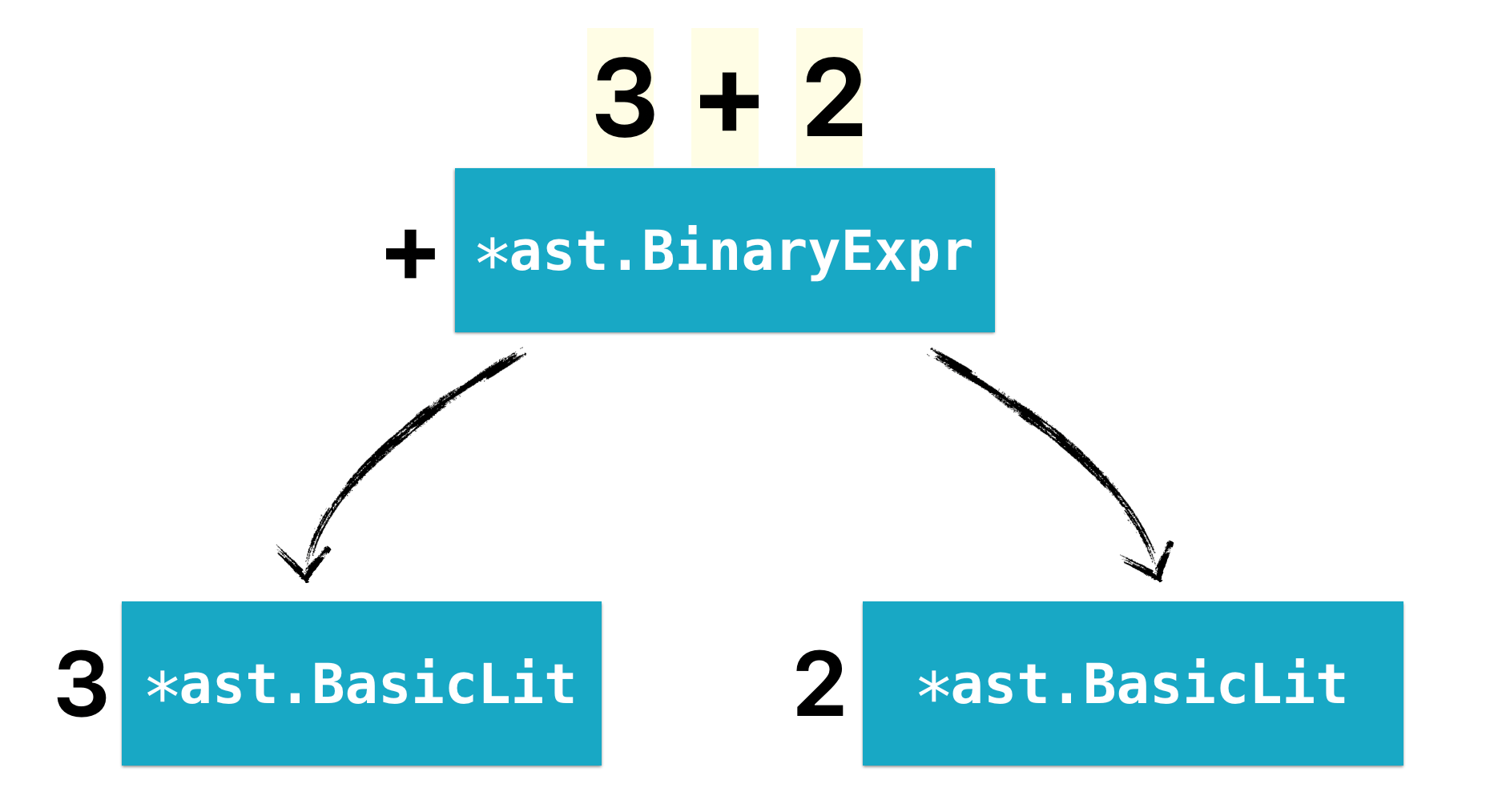
Now that we know what to look for, let's move on write the initial checker. Let us first parse the files (we're assuming the CLI only accepts files, not packages. We're going to cover packages later):
var files []*ast.File
fset := token.NewFileSet()
for _, goFile := range os.Args[1:] {
f, err := parser.ParseFile(fset, goFile, nil, parser.ParseComments)
if err != nil {
log.Fatal(err)
}
files = append(files, f)
}
Now that we have set of []*ast.File, let us inspect them and search for *ast.BinaryExpr occurrences. We know at this point what we're going to look for, so let us use ast.Inspect() to traverse the AST files:
for _, file := range files {
ast.Inspect(f, func(n ast.Node) bool {
be, ok := n.(*ast.BinaryExpr)
if !ok {
return true
}
if be.Op != token.ADD {
return true
}
if _, ok := be.X.(*ast.BasicLit); !ok {
return true
}
if _, ok := be.Y.(*ast.BasicLit); !ok {
return true
}
posn := fset.Position(be.Pos())
fmt.Fprintf(os.Stderr, "%s: integer addition found: %q\n", posn, render(fset, be)
return true
})
}
// render returns the pretty-print of the given node
func render(fset *token.FileSet, x interface{}) string {
var buf bytes.Buffer
if err := printer.Fprint(&buf, fset, x); err != nil {
panic(err)
}
return buf.String()
}
The main logic here is ast.Inspect(). I wrote it explicitly very verbose just to show all individual steps. After a while you can create re-usable functions in your analyzer to simplify the logic even more. We also created a simple render() function that renders the expression, so we can pretty-print the addition in a human readable form, a.k.a: 3 + 2.
Now, If you run this against couple of files you'll see that it works perfectly. However there are still few issues here. Do you know what these are? Here is one of the them:
package main
import "fmt"
func main() {
txt := "foo" + "bar"
fmt.Printf("Txt: %s\n", txt)
}
If we run addlint against this file, it'll report the addition! But remember, our requirement was that addlint should only show integer additions. So how can we solve it? With Types!
We need to type check the code as well to get the underlying types of the left and right hand side expressions. First let's type check the source code:
// import "go/types" and "go/importer"
conf := types.Config{Importer: importer.Default()}
// types.TypeOf() requires all three maps are populated
info := &types.Info{
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
Types: make(map[ast.Expr]types.TypeAndValue),
}
_, err = conf.Check("addlint", fset, files, info)
if err != nil {
log.Fatalln(err)
}
This will type check all the files we have passed and then populate the info variable's maps with all the necessary information. Because we're going to use info.TypeOf() method, we need to populate info.Defs, info.Uses and info.Types. After this, we're going to extend ast.Inspect to check the expressions as well:
ast.Inspect(f, func(n ast.Node) bool {
be, ok := n.(*ast.BinaryExpr)
if !ok {
return true
}
if be.Op != token.ADD {
return true
}
if _, ok := be.X.(*ast.BasicLit); !ok {
return true
}
if _, ok := be.Y.(*ast.BasicLit); !ok {
return true
}
isInteger := func(expr ast.Expr) bool {
t := info.TypeOf(expr)
if t == nil {
return false
}
bt, ok := t.Underlying().(*types.Basic)
if !ok {
return false
}
if (bt.Info() & types.IsInteger) == 0 {
return false
}
return true
}
// check that both left and right hand side are integers
if !isInteger(be.X) || !isInteger(be.Y) {
return true
}
posn := fset.Position(be.Pos())
fmt.Fprintf(os.Stderr, "%s: integer addition found: %q\n", posn, render(fset, be)
return true
})
As you see, we created a new isInteger() anonymous function that basically checks whether the expression we're passing is of type Integer or not. And then we use this function to check both the left and right-hand side of the *ast.BinaryExpr. This will now cover the edge cases where the addition doesn't contain integers.
Now that we know how to implement the addlint program with the low level go{token,parser, ast,types ...} packages, let's move on how we can use go/analysis to improve the overall CLI. (note: the above linter has still many edge cases, to keep it simple I'm leaving them as an exercise. If you want to fix some of them, try to check for 3 + 2 + 1 or a + 3 )
The go/analysis API

Let me show an example folder layout we're going to use. This layout is very popular and also a good starting point for any new linter:
.
├── addcheck
│ └── addcheck.go
├── cmd
│ └── addlint
│ └── main.go # imports addcheck
├── go.mod
└── go.sum
Here the core logic, will live inside the addcheck package. This will be then imported by the cmd/addlint main package, which when compiled will give us the addlint binary.
Now, back to go/analysis package.
In the heart of the go/analysis package is the analysis.Analyzer type. This type describes an analysis function: its name, documentation, flags, relationship to other analyzers and of course, its logic. Below you can see the definition(note: some of the fields and comments are omitted for clarity, we're going to explore them later):
// An Analyzer describes an analysis function and its options.
type Analyzer struct {
// The Name of the analyzer must be a valid Go identifier
// as it may appear in command-line flags, URLs, and so on.
Name string
// Doc is the documentation for the analyzer.
// The part before the first "\n\n" is the title
// (no capital or period, max ~60 letters).
Doc string
// Run applies the analyzer to a package.
// It returns an error if the analyzer failed.
Run func(*Pass) (interface{}, error)
// ... omitted fields
}
To create an analyzer we declare a variable of this type. Typically each Analyzer resides in a separate package which is then imported by the driver (main package running the tool, in our example it's cmd/addlint).
Let's start adding the skeleton for cmd/addlint, for that we're going to create a addcheck package that contains a declaration of the analysis.Analyzer variable:
// Package addcheck defines an Analyzer that reports integer additions
package addcheck
import (
"errors"
"golang.org/x/tools/go/analysis"
)
var Analyzer = &analysis.Analyzer{
Name: "addlint",
Doc: "reports integer additions",
Run: run,
}
func run(pass *analysis.Pass) (interface{}, error) {
return nil, errors.New("not implemented yet")
}
The core logic is implemented inside the run(...) function, which is not implemented yet. It accepts an *analysis.Pass type:
type Pass struct {
Fset *token.FileSet // file position information
Files []*ast.File // the abstract syntax tree of each file
OtherFiles []string // names of non-Go files of this package
Pkg *types.Package // type information about the package
TypesInfo *types.Info // type information about the syntax trees
TypesSizes types.Sizes // function for computing sizes of types
...
}
The *analysis.Pass is the core piece that provides information to the Analyzer's Run function. As you see it has all the necessary types that we need to analyze the source code, such as:
*token.FileSet[]*ast.File*types.Info
It has also handy functions, such as pass.Report() and pass.Reportf() to report diagnostics. Now let's implement the run(...) function:
func run(pass *analysis.Pass) (interface{}, error) {
for _, file := range pass.Files {
ast.Inspect(file, func(n ast.Node) bool {
// check whether the call expression matches time.Now().Sub()
be, ok := n.(*ast.BinaryExpr)
if !ok {
return true
}
if be.Op != token.ADD {
return true
}
if _, ok := be.X.(*ast.BasicLit); !ok {
return true
}
if _, ok := be.Y.(*ast.BasicLit); !ok {
return true
}
isInteger := func(expr ast.Expr) bool {
t := pass.TypesInfo.TypeOf(expr)
if t == nil {
return false
}
bt, ok := t.Underlying().(*types.Basic)
if !ok {
return false
}
if (bt.Info() & types.IsInteger) == 0 {
return false
}
return true
}
// check that both left and right hand side are integers
if !isInteger(be.X) || !isInteger(be.Y) {
return true
}
pass.Reportf(be.Pos(), "integer addition found %q",
render(pass.Fset, be))
return true
})
}
return nil, nil
}
As you see, everything is the same. The beauty of this function, compared to the previous, traditional way is that all the necessary information is ready and available for us. We don't have to parse the files, type check them or even find the correct position. It's all integrated into go/analysis.
addlint CLI
Let us now create our cmd/addlint CLI, the main package. The go/analysis package comes with several handy utilities and helper functions to create CLI checkers very easily. Below you'll see the content of the cmd/addlint main package:
package main
import (
"github.com/fatih/addlint/addcheck"
"golang.org/x/tools/go/analysis/singlechecker"
)
func main() {
singlechecker.Main(addcheck.Analyzer)
}
That's it! If you now build and run it with no arguments, you'll see this output:
$ addlint: reports integer additions
Usage: addlint [-flag] [package]
Flags: -V print version and exit
-all
no effect (deprecated)
-c int
display offending line with this many lines of context (default -1)
-cpuprofile string
write CPU profile to this file
-debug string
debug flags, any subset of "fpstv"
-flags
print analyzer flags in JSON
-json
emit JSON output
-memprofile string
write memory profile to this file
-source
no effect (deprecated)
-tags string
no effect (deprecated)
-trace string
write trace log to this file
-v no effect (deprecated)
This is amazing! The singlechecker package automatically created a CLI program for us and also populated with several important flags (for the curious ones, yes you can change them if you wish)
If we run it against any Go file, this is what we get:
$ cat foo.go
package main
import (
"fmt"
)
func main() {
sum := 3 + 2
fmt.Printf("Sum: %s\n", sum)
}
$ addlint foo.go
/Users/fatih/foo.go:8:9: integer addition found "3 + 2"
We successfully created our first linter with go/analysis! The benefits of using go/analysis is really huge. As you see this new approach makes things a lot of easier because you don't have to manually parse the files, type check them or even parse the flags! It's all integrated and ready to use. Compared to the old traditional style, the go/analysis package did the following for us:
- It automatically created a CLI program with all important flags via the
singlecheckerpackage - It parsed the files and created a list of all files in
[]*ast.Fileformat - It type checked all files and gave us a convenient
*types.Infovariable that contains the type information of the syntax trees - It provides us with convenient
Reportf()to report diagnostics
Now that we have a basic understanding of how go/analysis works under the
hood, let's move on to the actual core features and what makes it even better.
Depending on other analyzers
go/analysis has an built-in dependency graph which improves the performance of your checker if you're running multiple different diagnostics in a single CLI. A *analysis.Analyzer can depend on a different *analysis.Analzyer and if you run go/analysis it 'll make sure to first obtain and run the analyzers in the DAG (directed acyclic graph) in their respective order. Let us show this in a simple example.
As you know, I've omitted several fields in the *analysis.Analyzer when we defined them in addlint. One of the fields that I've omitted was analysis.Analyzer.Requires:
// An Analyzer describes an analysis function and its options.
type Analyzer struct {
// Requires is a set of analyzers that must run successfully
// before this one on a given package. This analyzer may inspect
// the outputs produced by each analyzer in Requires.
// The graph over analyzers implied by Requires edges must be acyclic.
//
// Requires establishes a "horizontal" dependency between
// analysis passes (different analyzers, same package).
Requires []*Analyzer
// ...
}
With the Requires field you can define a dependency to your Analyzer and go/analysis will make sure to run them in the correct order. The go/analysis comes with some useful analyzers that you can depend on while writing your own analyzer. One of them is the go/analysis/passes/inspect package.
The go/analysis/passes/inspect analyzer provides a building block that you can use instead of ast.Inspect() or ast.Walk() to traverse a syntax file. We have used ast.Inspect() in addlint to traverse the parsed files to find *ast.BinaryExpr's. However it's not very efficient if you have multiple analyzers and each of them have to traverse over and over the syntax trees!
The go/analysis/passes/inspect package is much more faster than ast.Inspect() as it uses the golang.org/x/tools/go/ast/inspector package under the hood. Here is is an excerpt from the package doc:
// ...
// During construction, the inspector does a complete traversal and
// builds a list of push/pop events and their node type. Subsequent
// method calls that request a traversal scan this list, rather than walk
// the AST, and perform type filtering using efficient bit sets.
//
// Experiments suggest the inspector's traversals are about 2.5x faster
// than ast.Inspect, but it may take around 5 traversals for this
// benefit to amortize the inspector's construction cost.
// If efficiency is the primary concern, do not use Inspector for
// one-off traversals.
package inspector
If your analyzer only has a single traversal then you don't need to use this package, however, if you're going to have multiple analyzers (such as go vet or staticcheck) then the go/analysis/passes/inspect is a great thing to have. Now let's add this to our addcheck package. First we add the Requires field and depend on the inspect analyzer:
var Analyzer = &analysis.Analyzer{
Name: "addlint",
Doc: "reports integer additions",
Run: run,
Requires: []*analysis.Analyzer{inspect.Analyzer},
}
After that we're going to modify our run() function and import the inspector:
func run(pass *analysis.Pass) (interface{}, error) {
// get the inspector. This will not panic because inspect.Analyzer is part
// of `Requires`. go/analysis will populate the `pass.ResultOf` map with
// the prerequisite analyzers.
inspect := pass.ResultOf[inspect.Analyzer].(*inspector.Inspector)
// the inspector has a `filter` feature that enables type-based filtering
// The anonymous function will be only called for the ast nodes whose type
// matches an element in the filter
nodeFilter := []ast.Node{
(*ast.BinaryExpr)(nil),
}
// this is basically the same as ast.Inspect(), only we don't return a
// boolean anymore as it'll visit all the nodes based on the filter.
inspect.Preorder(nodeFilter, func(n ast.Node) {
be := n.(*ast.BinaryExpr)
if be.Op != token.ADD {
return
}
if _, ok := be.X.(*ast.BasicLit); !ok {
return
}
if _, ok := be.Y.(*ast.BasicLit); !ok {
return
}
isInteger := func(expr ast.Expr) bool {
t := pass.TypesInfo.TypeOf(expr)
if t == nil {
return false
}
bt, ok := t.Underlying().(*types.Basic)
if !ok {
return false
}
if (bt.Info() & types.IsInteger) == 0 {
return false
}
return true
}
// check that both left and right hand side are integers
if !isInteger(be.X) || !isInteger(be.Y) {
return
}
pass.Reportf(be.Pos(), "integer addition found %q",
render(pass.Fset, be))
})
return nil, nil
}
If we build and run it again, it'll work the same way:
$ cat foo.go
package main
import (
"fmt"
)
func main() {
sum := 3 + 2
fmt.Printf("Sum: %s\n", sum)
}
$ addlint foo.go
/Users/fatih/foo.go:8:9: integer addition found "3 + 2"
Multiple analyzers
One thing that is great is how easy it is to implement and run multiple analyzers because of the built-in dependency graph explained above and the runners (drivers). For example, If you're using the latest Go version and run go vet, you're actually using go/analsyis with multiple analyzers. cmd/vet command's main function looks like this:
package main
import (
"golang.org/x/tools/go/analysis/unitchecker"
"golang.org/x/tools/go/analysis/passes/asmdecl"
"golang.org/x/tools/go/analysis/passes/assign"
"golang.org/x/tools/go/analysis/passes/atomic"
"golang.org/x/tools/go/analysis/passes/bools"
"golang.org/x/tools/go/analysis/passes/buildtag"
...
)
func main() {
unitchecker.Main(
asmdecl.Analyzer,
assign.Analyzer,
atomic.Analyzer,
bools.Analyzer,
buildtag.Analyzer,
cgocall.Analyzer,
composite.Analyzer,
copylock.Analyzer,
httpresponse.Analyzer,
loopclosure.Analyzer,
lostcancel.Analyzer,
nilfunc.Analyzer,
printf.Analyzer,
shift.Analyzer,
stdmethods.Analyzer,
structtag.Analyzer,
tests.Analyzer,
unmarshal.Analyzer,
unreachable.Analyzer,
unsafeptr.Analyzer,
unusedresult.Analyzer,
)
}
Here unitchecker is similar to singlechecker runner, but it accepts multiple analyzers (note: it also parses the packages in a different way, but let's assume it doesn't matter a lot for now). You can see all the registered analyzers by calling the help method of vet:
$ ~ go tool vet help
vet is a tool for static analysis of Go programs.
vet examines Go source code and reports suspicious constructs,
such as Printf calls whose arguments do not align with the format
string. It uses heuristics that do not guarantee all reports are
genuine problems, but it can find errors not caught by the compilers.
Registered analyzers:
asmdecl report mismatches between assembly files and Go declarations
assign check for useless assignments
atomic check for common mistakes using the sync/atomic package
bools check for common mistakes involving boolean operators
buildtag check that +build tags are well-formed and correctly located
cgocall detect some violations of the cgo pointer passing rules
composites check for unkeyed composite literals
copylocks check for locks erroneously passed by value
httpresponse check for mistakes using HTTP responses
loopclosure check references to loop variables from within nested functions
lostcancel check cancel func returned by context.WithCancel is called
nilfunc check for useless comparisons between functions and nil
printf check consistency of Printf format strings and arguments
shift check for shifts that equal or exceed the width of the integer
stdmethods check signature of methods of well-known interfaces
structtag check that struct field tags conform to reflect.StructTag.Get
tests check for common mistaken usages of tests and examples
unmarshal report passing non-pointer or non-interface values to unmarshal
unreachable check for unreachable code
unsafeptr check for invalid conversions of uintptr to unsafe.Pointer
unusedresult check for unused results of calls to some functions
...
If you checkout some of the analyzers, such as structtag, you'll see it uses Requires to depend on the inspect analyzer. go vet is therefore highly performant because of this new design provided by the go/analysis framework.
Summary
I hope this blog post provided you a good introduction to start using go/analysis. There are still a lot of things that I've didn't covered yet. go/analysis is very powerful and has many features that make analyzing Go code simple and efficient. For example one of these features is Facts. This can be achieved by using analysis.Fact interface. When you analyze something, you can produce facts (annotations) for a given analyzer and later import these Facts from another analyzer. This allows you to create very powerful and efficient combinations with multiple analyzers.
All the code written here can be found in the github.com/fatih/addlint repo if you want to play with it. If you have more questions about go/analysis make sure to join the Gophers Slack #tools channel where many Go developers discuss issues and problems around go/analysis.
Update
I wrote a new blog post about how to extend your linter to add suggested fixes. Suggested fixes let your linter to rewrite your source code by passing
the -fix flag. For more information check out the new blog post: Using
go/analysis to fix your source
code
Thanks for reading!